ZZ: Bleeding Edge版V8引擎的内存使用评测
老韩说:未经许可,严禁转载... 哈哈,所以我只转载一个链接: 秀码趣:Bleeding Edge版V8引擎的内存使用评测
这篇文章背后是我们暑期实习生训练营的成果,非常高兴看到他们的成长!
以后俺们如果开始发布 sohu developer blog 的话,除了 linux@SOHU 之外,看来可以增加一个 NodeJS 的专栏.. :)

老韩说:未经许可,严禁转载... 哈哈,所以我只转载一个链接: 秀码趣:Bleeding Edge版V8引擎的内存使用评测
这篇文章背后是我们暑期实习生训练营的成果,非常高兴看到他们的成长!
以后俺们如果开始发布 sohu developer blog 的话,除了 linux@SOHU 之外,看来可以增加一个 NodeJS 的专栏.. :)
September 13, 2011
几乎所有google的服务都是通过 Internet 交付给用户使用,因此该公司特别有动力改进网络的运行模式。在2011召开的Linux Plumbers Conference featured presentations的网络会议上,三个google的工程师各提出了一个对网络有显著改变的建议。从他们三个人的建议可以看出,networking 还有很大的改进空间。
Proportional rate reduction
这个“拥塞窗口”主要取决于TCP发送者的想法:在中间环节超载的情况下,多少的数据能够被传送至末端。丢弃包常常意味着拥塞窗口过大,因此需要TCP正常实现过程中减少窗口当丢失发生时。但是减少拥塞窗口,就会减低性能;如果丢包仅是一次性事件,减少窗口大小是完全没必要的。RFC3517描述了一种算法,以使一次丢包后,加快连接速度。但是Nandita Dukkipati说,我们可以做的更好。
根据Nandita的说法,Google 的网络会话出问题的大部分原因集中在一个点上,它将导致花费7-10倍的时间才能完成会话。RFC3517是这个问题的一部分。这个算法当一次包丢失后,会立即减少一半的拥塞窗口,意味着发送者必须等待ACKs一半在传输途中的包(如果丢失包后拥塞窗口还是满的)。这就导致发送者将保持更长的等待时间。在简单的情况下(单个包丢失在长时间的传输过程中),这种做法是足够好的。但是在处理短数据流或很大比例的包丢失时,将阻碍工作。
现在的Linux系统没有使用严格的RFC3517。它被一个改进的算法“率减半”所代替。拥塞窗口不会立即减半。一旦 TCP 开始尝试恢复丢失包,每个ACK(主要是告诉末端两个包的接收者)将引起拥塞窗口大小减少。在传输过程中的全套发生上述过程,窗口大小将减半,但是发送者将持续发送(低速率)。这种方案最终的结果是减缓数据流和降低等待时间。
但是率减半还有提升空间。ACKs依赖于自身;延长的损失将显著引起拥塞窗口数量的减半和恢复的缓慢。这个算法也没有处理拥塞窗口的速率达到最高的可用值的过程,直到整个恢复过程完成后,速率才到达最高值。因此这将花费更长的时间来返回到最高速率。
成比例速率减少算法采用了一种不用的方法。第一步就是评估和计算传输的数据量,然后根据拥塞控制算法,计算拥塞窗口数量是多少。如果在管道中的数据量小于目标窗口的值,系统将直接进入TCP慢启动算法来备份窗口。然而当连接中发送大量丢失时,边开始重建窗口,而不是长时间匍匐一个小窗口。
相反如果传输的数据量至少达到了一个新的拥塞窗口,一个相似的率减半算法将被使用。相对新的拥塞窗口计算实际的减少量,而不是严格的减半。对于大和小的丢失,注重于使用评估的传输数据量,而不是请求的数据量。这使得恢复更加顺利和避免不必要的窗口数量的减少。
那多少是最合适的呢? Nandita认为,根据google在一些系统上已经运行的实验结果显示,平均等待实际减少3-10%。恢复实际减少5%。这个算法已经广泛应用于google服务器上;该算法也被3.2开发周期所合并。更多的信息请查看这份 draft RFC。
TCP fast open
打开一个TCP连接需要一个three-packet 握手:客户端发送一个SYN(连接请求)数据包,服务端返回一个SYN-ACK(确认)响应,以及最后由客户端发出的一个ACK(确认)。直到握手完成,连接才可以传送数据,所以握手机制在每个连接都有一个不可避免的开始延迟。但是,问问Yuchung Cheng,如果想要在握手数据包中携带数据信息将会发生什么。对于一些简单的事务,例如一个接下来要发送一个页面内容的HTTP GET请求,伴随着握手数据包发送相关联的数据将会消除延迟。这个想法的结果就是TCP fast open的设想。
RFC 793(关于TCP的)确实允许数据包含在握手的数据包中发送,数据被限制为在握手完成之后再被 tcp 栈传递给应用程序。这样就可以通过避免最后一次请求来加速一次TCP连接发送数据的进程,但是还有一些障碍需要解决掉。一个很明显的问题就是会加大SYN泛滥攻击的几率,即使它们只影响内核后果也足够糟糕;如果每个接收到的SYN数据包都要占用应用程序的内核资源,那么拒绝服务的可能性就会变得很大。
Yuchung叙述了一种快速打开的方法试图解决大部分的问题。第一步是每个服务器创建一个 per-server secret,然后根据每个客户端的信息 hash,给每个客户端生产 per-client cookie。当客户首次发起 TCP SYN 请求时,这个cookie被作为一个special option包含在 SYN-ACK数据包中发送到客户端;客户端可以保存它,然后在未来的fast open时利用它。首先得到cookie的需求是一种低端的防止SYN泛滥攻击的方法,但是它确实让攻击变得有些困难了。另外,server端的secret可以相对频繁的更改,并且,如果当server发现有很多的连接时,fast open将会被禁用,直到连接数目回归正常。
一个仍然存在的问题是,互联网上大概有5%的线上系统将会丢弃那些包含了未知option数据的SYN数据包。这种情况下TCP fast open就无法使用了。客户端必须记住那些fast-open SYN数据包没有发送成功的cases,以后再遇到这些cases就使用普通打开。
缺省情况下fast open不会发生;连接双方的应用程序都必须特地的要求使用它。在客户端,sendto()系统调用就是用来请求一个fast-open连接;伴随着新的MSG_FAST_OPEN标志, 它的功能就像是connect()与sendmsg()的结合。在服务端,伴随着TCP_FAST_OPEN option 的setsockopt()调用将会允许fast opens。不管哪种方式,应用程序都不用担心去处理类似fast-open cookies这样的问题。
在google的测试中,TCP fast open已经被证实可以减少4%到40%的页面载入时间。自然的,在连接往返时间开销很大的情况下这项技术效果最好;延迟越高,移除它的价值就越大。很快,一个实现了这个特性的patch将会被提交。
Briefly: user-space network queues
之前的两个讨论都是在关注提高数据在网络上传输的效率问题。Willem de Bruijn则是关注与在本地主机上的网络进程。特别是,他是在使用高端的硬件工作:高速的网络连接,数目众多的处理机,并且,更重要的是,它拥有可识别特定流然后直接把包传入特定连接队列的智能网络适配器。当kernel感知到这个数据包的时候,它早已被接收并放置在合适的位置等着应用程序来请求数据了。
实际的对数据包的处理工作将会在应用程序的上下文环境中执行。所以"合适的位置"这里还包括了正确的上下文和正确的CPU。在软件IRQ级的中间处理就省略掉了。Willem甚至描述了一个新的接口,靠它应用程序可以通过一段共享内存段直接从kernel接收数据包。
换句话说,这段讨论描述了几种网络通道的概念,通过它们数据包被尽可能近的推送到应用程序。还有大量的细节问题需要涉及,包括为了类似防火墙等原因导致的通道挂起。利用 sysfs 向用户空间发送数据包的建议很难通过评审。但是这项工作最终可能会达到一个普遍有用的地步;有兴趣的人可以在 the unetq page 处找到patches。
翻译:靳彬
原文:Ensuring data reaches disk
September 7, 2011
This article was contributed by Jeff Moyer
在理想的情况下,系统崩溃、断电、磁盘访问失败这些情况是不会出现的,开发者编写程序时也不用为这些情况担忧。不幸的是,这些情况比我们想像的还经常出现。本文描述了数据是怎样一步步被写入磁盘上的,尤其是其中被缓冲的几个步骤。本文也提供了数据被正确写盘的最佳实践,以确保意外发生的时候,数据不会丢失。主要是面向 C 语言的,其中的系统调用也有其它语言的实现。
I/O缓存
考虑到开发系统时数据的完整性,有必要理解系统的整体架构。在数据最终存入稳定存储器前,可能会经过多个层,如下图所示:

处于顶层的是需要将数据写入永久存储的应用程序。数据最初存在于应用程序的内存或缓存中的一个或多个块中。这些缓存中的数据可能被提交给一个具有自己缓存的库。抛开应用程序缓存与库缓存,这些数据都存在于应用程序地址空间中。数据经过的下一层是内核,内核有一个叫做页缓存的回写缓存。脏页会存放在页缓存中一段时间,这段时间的长短取决于系统的负载与I/O模式。最后,当脏数据离开内核的页缓存时,会被写入存储设备(如磁盘)。存储设备可能会进一步将数据缓存在临时的回写缓存中。如果这时发生了断电的情况,数据可能会丢失。最后一层是稳定存储。当数据到达这层时,就可以认为数据安全存入稳定存储器了。
为进一步说明分层的缓存,来看一个在 socket 上监听连接的程序,它把从各个客户机收到的数据写入一个文件的应用程序。在关闭连接前,服务器要确保数据写入稳定存储设备中,并向客户机发送确认信息。
第5行是一个应用程序缓存的例子;从socket中读取的数据被存入这个缓存中。现在,要传输的数据量已经知道,由于网络传输的特性(可能会是突发的或缓慢的),我们决定使用libc的流函数(fwrite() and fflush(),由上图中的"Library Buffers"表示)进一步缓存数据。10到21行负责从socket中读取数据,并写入文件流。在22行时,所有的数据都已经被写入文件流了。在23行,文件流进行刷新,并把数据送入内核缓存。然后,在27行,数据被存入稳定存储设备。
I/O APIs
既然我们已经深入了解了API与层次模型的关系,现在让我们更详细的探寻接口的复杂性。对于本次讨论,我们将I/O分为3个部分:系统I/O,流I/O,内存映射I/O。
系统I/O可以被定义为任何通过内核系统调用将数据定入内核地址空间中的存储层的操作。下面的程序(不全面的,重点在写操作)是系统调用的一部分:
Operation Function(s) Open open(), creat() Write write(), aio_write(),
pwrite(), pwritev()Sync fsync(), sync() Close close()
流I/O是用C语言库的流接口进行初始化的I/O。使用这些函数进行写的操作并不一定产生系统调用,即在一次这样的函数调用后,数据仍然存在于应用程序地址空间中的缓存中。下面的库程序(不全面)是流接口的一部分:
Operation Function(s) Open fopen(), fdopen(),
freopen()Write fwrite(), fputc(),
fputs(), putc(), putchar(),
puts()Sync fflush(), followed by
fsync() or sync()Close fclose()
内存映射文件与系统I/O类似。文件仍然使用相同的接口打开与关闭,但对文件数据的访问,是通过将数据映射入进程的地址空间进行的,然后像读写其它应用程序缓存一样进行读写操作:
Operation Function(s) Open open(), creat() Map mmap() Write memcpy(), memmove(),
read(), or any other routine that
writes to application memorySync msync() Unmap munmap() Close close()
打开一个文件时,有两个标志可以指定,用以改变缓存行为:O_SYNC( 或相关的O_DSYNC)与O_DIRECT。对以O_DIRECT方式打开的文件的I/O操作,会绕开内核的页缓存,直接写入存储器。回想下,存储系统仍然可能将数据存入一个写回缓存中,因此,对于以O_DIRECT打开的文件,需要调用fsync()确保将数据存入稳定存储器中。O_DIRECT标志仅与系统I/O API相关。
原始设备(/dev/raw/rawN)是O_DIRECT I/O的一种特殊情况。这些设备在打开时不需要显式指定O_DIRECT标志,但仍然提供直接I/O语义。因此,适用于原始设备的规则,同样也适用于以O_DIRECT方式打开的文件(或设备)。
同步I/O(O_DIRECT或非O_DIRECT方式的系统I/O,或流I/O)是任何对以O_SYNC 或O_DSYNC方式打开的文件描述符的I/O.以下是POSIX定义的同步模式:
用以对文件描述符进行写调用的数据与相关的元数据,在数据进入稳定存储时,生命周期结束。注意,那些不是用于检索文件数据的元数据,可能不会被立即写入。这些元数据包括文件的访问时间,创建时间,和修改时间。
值得指出的是,以O_SYNC 或 O_DSYNC方式打开文件描述符,并将其与一个libc文件流联系在一起的微妙之处。记住,对文件指针的fwrite()操作会被C语言库缓存。直到fflush()被调用,系统才会知道数据要写入磁盘。本质上来说,将文件流与一个同步的文件描述符关联在一起,意味着在fflush()操作后,不需要对文件描述符调用fsync()。
什么时候执行fsync操作?
可以根据一些简单的规则,决定是否调用fsync()。首先,也是最重要的,你必须明白:有没有必要将数据立即存入稳定存储中?如果是不重要的数据,那么不必立即调用fsync(). 如果是可再生的数据,也没有太大的必要立即调用fsync()。另一方面,如果你要存储一个事务的结果,或更新用户的配置文件,你很希望得到正确的结果。在这些情况下,应该立即调用fsync()。
更微妙之处在于新创建的文件,或重写已经存在的文件。新创建的文件不仅仅需要fsync(),其父目录也需要fsync()(因为这是文件系统定位你的文件之处)。这类同步行为依赖于文件系统(和挂载选项)的实现。你可以对专门为每一个文件系统与挂载选项进行特殊编码,或者显示调用fsync(),以确保代码的可移植性。
类似的,当你覆盖一个文件时,如果遭遇系统失败(例如断电,ENOSPC或I/O错误),很可能会造成已有数据的丢失。为避免这种情况,通常的做法(也是建议的做法)是将要更新的数据写入一个临时文件,确保它在稳定存储上的安全,然后将临时文件重命名为原始的文件名(以代替原始的内容)。这确保了对文件更新操作的原子性,以使其它读取用户得到数据一个副本。以下是这种更新类型的操作步骤:
错误检查
进行由库或内核缓存的写I/O时,由于数据可能仅仅被写入页缓存,例如在执行write()或fflush()时,可能会产生不被报告的错误。相反,在调用fsync(),msync()或close()时,由写操作产生的错误会被报告。因此,检查这些调用的返回值是很重要的。
写回缓存
这部分介绍了一些关于磁盘缓存的一般知识,与操作系统对这些缓存进行控制的知识。这部分的讨论不影响程序是如何构建的,因此,这部分的讨论是以提供信息为目的的
存储设备上的写回缓存有多种形式。有我们在这篇文章中假设的临时写回缓存。这种缓存会由于断电而丢失数据。大多数存储设备可以通过配置,使其运行在 cache-less 模式,或 write-through 模式。对于写操作的请求,每一种模式,只有当数据写入稳定存储时,才会成功返回。外部存储阵列通常具有非临时的,或具有后备电源的写缓存。这种配置,即使发生了断电的情况,数据也不会丢失。程序开发者可能不会考虑到这些。最好能够考虑到临时缓存与程序防护。在数据被成功保存的前提下,操作系统会尽可能的进行优化,以获得最高性能。
一些文件系统提供挂载选项,以控制缓存刷新行为。从2.6.35的内核版本起,ext3,ext4,xfs和btrfs的挂载命令是"-o barrier",以打开写回缓存的刷新(这也是系统缺省的),"-o nobarrier"用以关闭写回缓存的刷新。之前的内核版本可能需要不同的命令("-o barrier=0,1"),这依赖于不同的文件系统。程序开发者不必考虑这些。当文件系统的刷新被禁用时,意味着fsync调用不会导致磁盘缓存的刷新。
原文:What Google App Engine Price Changes Say About the Future of Web Architecture
翻译:安冲、许力波、林业、曾怀东、朱翊然、马少兵、李凯、王鑫、靳彬
当我还是一个孩子的时候,我像孩子一样说话,像孩子一样理解,像孩子一样思考:但是当我成为一个成年人的时候,我收起了那些幼稚的东西。--Corinthians
随着GAE新的定价模式调整,开发将会由成本驱动。为了使我的应用更好更快,我喜欢去优化它们,但是仅仅为了成本的便宜而去优化无疑是一种时间的浪费。-- Sylvain on Google Groups
当 GAE 摆脱幼稚,成长为一个真正的产品的时候,"pay for what you use"的美梦破了。价格改变,体系随之改变,用户随之改变,理想随之改变,但 GAE 将继续存活。
Google正在关闭很多它的项目。GAE没有被关闭。我们应该感谢由于它定价的调整而让它在更残酷环境下依然可以存活吗?如果没有迅速地向盈利转向,GAE毫无疑问仅仅将会成为诸多想法长卷中一个历史性的脚注。其涉及的迫切性由GAE提供定价百分之五十的优惠以及在多线程版本的Python铺开之前转向新的定价模式所清晰的反映出来。
梦想是美丽的:为你所使用的服务进行支付并且使得它绝对地容易使用。现在这一点很容易理解。这是公平且令人信服的。GAE曾经用了三年时间进行试运行来让梦想实现,结果是这显然是个噩梦。这是它的耻辱。Google是大胆的,他们创造新的事物。他们工作努力。GAE革新了可伸缩的应用程序的发展以及以原始和有趣的方式扩展了PaaS。他们做了惊人的工作。并且结果是被很多人喜欢甚至是热爱的。但是经济原因使他们失败了,他们不得不进行转折。这是困难的。转变的结果会是什么呢?
Pay for what you use has changed。GAE从一种将定价绑定在实际CPU使用上的抽象资源驱动模型转向为Amazon模式的将定价绑定在实际物理资产全部花费上的事例驱动模型(请参考 FAQ )。估计GAE新的定价模式将使对其使用的成本增加到2倍到10多倍。
Dead easy has changed。定价只是故事的一部分。GAE仍然承诺它的整体平台零成本维护的保障,但是更多的压力施加给了程序员来浏览新的定价模式并且重新进行复杂的编码来减少成本。GAE已经不再容易使用了,工作重心已经转移到更良好的编程上。
Wesley Chun,来自于Google's developer relations。做了一个试图解释变化背后原因的具体工作(摘要):
一切都非常合理。作为优质的企业级产品,定价不必遵循成本,价格可以上升,以应付竞争,甚至更高,如果你认为你的产品具有特殊的价值。
诚然GAE开始不是这样子的。GAE开始采用一个低廉的价格,易于每个程序员使用的基于CPU使用率计费的平台。现在一切都不是这样了。以前的方法行不通,也许是因为太早了,so it's hard to shake that there's a bait-and-switch feel to this
转向 premium branding 尤其令人惊讶,因为它从来没有被 Google 定义为一个 premium service。从商业角度来看是有道理的,但这是为什么对所有的一切有这样轰动的部分原因
GAE现在要做的是一个企业级的服务。其他产品上赚到的钱将支付给它。它不再定位给那些希望托管于较低成本的GAE架构的开发者,而是定位在开发应用程序来赚钱的开发者。现存应用程序的大小,类型和业务模型,将不适合GAE了。
这是一个非常尖锐的转变。但是,让你做些什么才能生存。必须作出选择真的很难。当我们经历了所有悲痛的阶段,我们必须克服它,重新评估,并继续前进。
mdasen 很好的描述了这些早期日子里令人陶醉的感觉:
Hey hackers! 你必须在我们Google的系统上完全重写你的应用程序,因为我们的系统要比其他系统高效很多。有一些烦人的限制你必须去习惯,对一些事情也非常头疼。尽管如此,我们的服务在负载的使用上很便宜,甚至之后你只要对no-hassle-scaling上花费少量的编程时间,比你用过任何的托管都少!
With equal poignancy Stephen, in this Google Groups thread, captures the feeling of today:
现在的状况是"App Engine"成为了"App Engine for Business",以前那个"App Engine"不复存在了。Google 已经明确了这一点。App Engine现在是一个企业级产品,价格与成本并没有关系。
梦的延续
现在我们可以回顾一下,这只不过是一个实验期…一个实验因为一个关键的方面而失败:基于付费模型的资源似乎不起作用了。
我们震惊的一部分是价格全面上涨。我们通常认为的计算资源随着时间的推移变得便宜。摩尔定律和规模经济相结合一直是我们的好朋友。可伸缩性是朝着相反的方向流动,Google要求用户预算可伸缩性,而开发者则不必。
但是,这个问题不只是盈利和亏损,本实验的结果对于未来应用体系结构有一些有趣的影响。现在,我们要讨论这个话题
我过去完全想错了,我曾以为 GAE 将发展成为一个任务队列
说一下我这个错误的预测吧,GAE 的发展和我猜测的方向截然相反:我以为 GAE 会完全抛弃 instance image 概念,转向在一个巨大的任务队列容器上编写应用程序。
这个猜想/远景的基础是一个GAE最具创新性和深远的特点的发展和演变:任务队列。它的一个大的特征是允许将应用程序分解成异步流。任务进行排队,并在一段时间后执行。取代最初用于GAE上的 monolithic 和同步模型,应用程序可以完全异步,并且可以在任何机器上运行。现在我们清楚 monolithic 的前端实例已经成为任务队列结果的冗余。
问题是任务队列仍然基于镜像。URL可指定一个操作,来终止任务队列里的一个运行时实例,其代码模板是从镜像中读取。一个镜像包含了一个可执行的应用程序的所有代码。这就是 monolithic。
但当客户端调用 URL 的时候,就开始执行一个 monolithic 镜像内的代码。正是因为这些大的镜像必须通过GAE来管理,所以Google需要向你收取更多费用。他们管理需要资源,耗费初始化时间和运行时内存,尽管你的应用没有做任何其他事情。
一个不同的想法就是为什么我们不是简单的请求中止任务队列中?不再使用 monolithic 镜像,而是异步模型。是的,GAE将不得不继续以某种特殊的方式管理并发布这些代码库,任务并不简单。但是这将解决资源粒度如何被更好的分配和衡量的问题,而不是像现在这样把 image 作为代码分发的单元,把实例作为执行的单元。下面我们将会更多的讨论粒度问题。
所以,伴随着这个非常酷的任务队列框架和编程模型的发布,我感觉他们肯定已经做好了准备,宣布 monolithic image 将要消失,实例将要消失,将有更精细的支付以替代您所使用的计费模式。我又一次错了。
这是一个量子力学问题
驱动这个剧变的是,程序运行在一个与资源量化方法与物理机完全不同的抽象机上。一个服务器只有这么多的内存和CPU。即使程序是空转的,运行它也是要使用内存的。Google必须为实例所使用的资源付费,只承担程序运行所使用的资源的费用,而不是承载一个程序所使用的所有的资源,这就在两个模型之间造成了一个不可持续且无利可图的定价摩擦。
另一种说法,程序部署的量很大,但是运行的量却很小。一个较小的工作粒度将允许作业被安排在空闲的时间,这就是为什么我觉得任务队列模型很优秀。
在实践中我们看到了这个效果。一个使用.02cpu时间的应用程序现在或许会用掉2.8实例时间。过去,如果你正确的编码你的应用程序,GAE看起来就像一个巨大的CPU,尽可能少的CPU资源被使用到了。现在,GAE已经激增为一个组件集(前端,后端,调度器等)
现在,最小化 CPU 的运行时间已经没啥意义了。如果应用程序因为 IO 被阻塞(编译者注:被OS挂起因此也没有CPU时间的消耗)仍然会被要求付费。一个实例执行多长时间,你就得花多少钱。实例消耗时间去启动,所以不管这个启动时间对你是否有意义,你都要支付15分钟的花费。而且如果一个请求在调度器看来将会消耗很长的时间,更多的实例将会被spun up。我觉得这一点你真的不能争执。关键是改变了资源是如何共享的。转变到实例模型是某种意义上的放弃。
如果 Google 认为内存是一种稀缺资源的话,很多人都要求把 CPU 计费和内存计费分离。这会要求应用更有效率的使用内存。(编译者注:这句话的意思是,很多人认为 GAE 的调价的成本压力是来自内存)问题是,对于一个实例,内存和CPU并不是可独立的。这也是为什么Google不能制做一个完美的高效的调度程序,作业单位并不匹配计算资源的单位。
成本上升
因为在新的计费模式下,实例时间增加了,所以花费增加了。Python多线程编程能帮助解决这个问题,但是在数据存储行为上的开销也在增加。
The Amazing Story Of AppEngine And The Two Orders Of Magnitude
Emlyn O'Regan写了一篇非常棒的文章详细解释了他在新的定价模式中调整自己应用的经验。他后来接着发表了 AppEngine Tuning #1
最开始,像大多数人一样,他忽略了原来的公告,他认为变化不大,但实际刚好相反。他的账单从$0.51/day 上涨到了$49.92/day。原来一年$200 的花费变成了一年$20K。这是一个巨大的上涨。
Emlyn随后做的事情很cool,他带着我们浏览了一遍他的app,找出钱花在哪里,以及他对自己的app做了怎样的改变来减少使用Google工具和文档的花费。在新的模式下我们找到了以前不是问题但是现在是的一些行为。
这些行为包括:
一些问题是由于"just make it work"这样的设计模式而导致的. 这在项目中很典型。GAE的新定价机制使这种不严格的代码变得花费巨大,所以需要对它们进行修改。好事情是,架构不得不从现在开始考虑这些问题。最小化实例数以及最小化数据库操作。一定要检查这些。
对于GAE来说,这会减少整体资源的使用,这也是他们所期望的。发出合适的定价信号是实现这一结果的最有效的方法。
其他问题还包括由于无意的GAE API调用造成的意外结果。在API中的后果应该更明显。由于它非常微妙而且具体app有着区别,我们需要时间来解决这些问题。
Scheduler 有利益冲突问题
scheduler 的工作是在计算机集群中安排工作。在这种情况下,工作的形式包括web请求, cron jobs以及任务。所以引入了工作队列。这项工作需要以合理的方式分配资源。那么什么在处理工作呢?是实例。实例的运行占用内存,CPU,硬盘以及带宽,这意味着运行实例需要付费。切换(spin up)实例需要固定的时间,不管工作的性能如何 切换实例也需要付费。并且由于它们花费固定的代价运行,让它们在有较多负载的情况下运行更为合理。GAE并不知道你将会造成怎样的负载。GAE的负载是由一个随机过程造成的。
想彻底解决这个问题非常困难。在实时调度中,不可能确定的安排一个变化的工作负载。即便通过系统运行同样的工作负载,在不同时刻也有不同的结果。这是由cpu定价转变为实例定价造成的奇怪后果。
很多人抱怨GAE scheduler是一个内在利益冲突的矛盾体。 scheduler决定了实例运行的数量,实例运行数量反过来决定了盈利。这是一个好主意么?这种激励方式是错误的。如果开发者和GAE都有类似的激励机制会比较好,现在他们本质上是相反的。
并且,注意到google在广告方面有相同的 edge。google建立这些数据的索引,创造市场,取走广告,设定价格,并且决定广告在何时显示。这所有的一切像GAE scheduler一样对公众是不透明的。我回忆起弗洛伦萨的美第奇家族,他们通过简单的控制那些可以参与选举的人来控制公众选举的结果。
一个存在潜在冲突的令人关注的地方是认购超额。如果你分给每个应用许多RAM而google不能在同台机器上运行太多的实例,因此RAM在前端被限制在了128M以内,在后端限制在了1G以内。像其他的托管服务一样,超额订购这些资源可以使单台机器挣得更多的钱。那样可能导致交换、系统颠簸等问题,这些问题可能导致更高的延时从而需要申请更多的实例。两个方面都需要钱。而且低内存的限制使得更难去写更大的多线程应用程序,这些程序是降低延迟以及减少实例数量的策略之一。
为了解决所有的问题,许多的压力正在放到scheduler上。我们会使调度变得更好,这里面包含了你的费用。就个人而言,由于我们之前讨论的粒度错配问题,我不太清楚那样会真正的起作用。
问题在于程序员要负责平衡所有的这些目标。Gubbi表达了这种进退两难的感觉:
我抱怨的是,新价格让延迟成为了关注的焦点,然而开发者只能在应用程序代码的层面去优化它。应用程序和基础设施都应该为延迟负责。
以前是基于如何实现业务目标的策略驱动的架构,而如今程序员将在他们的程序中硬编码一个设计模型。当所有的假设发生变化时,代码会很难改动。这所有的需求将提升到抽象的水平上。例如,当一个任务是低优先级的,scheduler会说我们不需要为它而加速实例,让我们利用空闲时间再去调度它吧。
Steve已经在scheduler配置文件和请求设置文件中做了一系列的好的scheduler变化的建议,主要的思想是基于请求头和其他我们能够在那个级别上获得的信息的基础上在预定义的调度配置文件中过滤请求的能力。
From Barry Hunter:
“旧”的方式,非常提倡低cpu的使用,即使那样可能带来高延迟的代价。缓慢请求时,将会花费大量的实例 - google的成本。
“新”的方法推崇降低你的延迟。快速的请求带来每秒钟(每个实例)更多的查询。这意味着更少的实例。
通过收取实际使用实例的费用,他们能够有助于压低实例的数量。
因此开发人员应该以压低实例的数量为目标--为了省钱。
那些需要,想要,(或者懒得去优化),慢的请求将要支付 - 接近于google实际的开销的钱。
Google不希望你spinning up 实例并且很快的把他们撤下来。Its that spinning up, that 'costs'.
故障排除指南
johnP 觉得编写一个 trouble shooting guide 来应付价格变化是一个好主意。他的第一个草案是:
检查google的文档
google有一些值得看的好文档:
Optimize for One Instance
Joshua Smith:
我正在优化单一实例的情况,其实我只是实现了一个简单的缓存。第一次命中kiosk时生成页面并且返回它,而且在内存中保存该页面。第二次命中时从内存中获得缓存的页面。这要比我原来的方案好很多,因为在kiosk进行页面重载时我保护了任何异常发生的情况。
Task Scheduler Bunching
Joshua Smith:
尽管大家着眼于任务队列与调度器交互这种方式,但是出现了另外一种情况,任务队列趋向于聚集任务,将任务并行地导入到调度器去加速产生一个新的实例。我觉的,必须首先考虑等待任务的数量,然后考虑加速实例的产生来处理队列。如果仅仅有两个实例,必须使他们等待很短的时间。(当然,如果能够给用户控制权限更好,凭借设置任务的优先级)
Dump Writes to Queue
peterk:
第一种类型的请求,将被写入到任务队列,立即得到返回结果。队列将被后台的实例处理。虽然目前这种类型的花费有所上升,但是主要的优势是我基本上得到了对那种写队列被处理的大量控制。AppEngine不会为我加速处理新的前端实例。这样我就可以随意控制想多快,多少钱,来写。将会出现一个延迟,在将数据写入到数据库之前。但是我认为这点可以承受。
Use Cursors
Tim Hoffman
再看看游标,如果你想对一个数据集操作,也没有多大的性能问题的限制或抵消。
Use Pull Queues, Backends, and Cron
Tim Hoffman
我将考虑使用一个pull队列来处理你的任务负载,代替正常的push队列。这种情况下,我们可以用使用计划任务工具来限制任务加速的数量,以及在一个连续模式下使用离线处理方式。想的越多,我觉得这个过程适合后端和计划任务工具,而不是前端和任务队列。
Two Stage Gets Preferred
Google App Engine Post-Preview Pricing FAQ:
这种新的计费模式,仍然是很经济的,对处理获取1000个 keys-only 的查询,和得到500的数据,相比正常的查询(non keys-only)来得到全部1000数据。第一种是更加的经济。获取1000keys+500entities=$0.0001+0.00035=$0.00045;而第二种花费0.0007美元。
Stop the Bots
In Googlebot Spawning New Instances, Jeff Deskins notices something very interesting
当我们着眼于降低在AppEngine的费用时,googlebot抓取页面的速率为12页/s。这将导致另外6个实例被创建。
另一个低优先级 spiky 表现的例子同样导致花费增加,由于每个爬虫都在消耗费用,整个抓取网页的的思路都需要改变——Spiky App Penalty
处罚“spiky应用”的费用的方式太多。三年前,当我们首次启动一个GAE应用时,看准了下面的三点:伸缩性、以模式付费,简单。
我们的应用是非常“spiky”-单个用户一次产生50次请求,需要服务器快速响应。我们的应用已经在该平台上运行了三年时间,并根据GAE的规则修改了代码,使得代码能够运行在伸缩性和其他的约束条件下,并且运行良好。我们没有其他的选择,如果我们使用EC2或者其他的系统。
这种新的计费模式导致我们有两个麻烦:为空闲的实例付费、目前的模式失去简单性和可预见性
有些人建议,这种新的调度模式需要一个灵活性,来处理小和束缚的应用。你的这种计费模式却没有考虑考到大量用户---首次想用你工具,以及那些利用你的早期限制和约束来开发的人。
无法确定的成本
这种调度程序对编程人员来说是个黑盒,隐藏了核心的空间算法,使得很难理解。不能被控制,不能评理。控制实例和带宽,比控制CPU的应用将更困难。这导致了很多不确定的困惑。难道这就是世界新秩序的一部分吗?
Instance Idea Includes both CPU and RAM
FAQ的作者Greg D关于为什么GAE不为RAM建立一个单独的收费机制
例如我们已经通过charging增加了一个RAM charge。通过拥有一个实例分配的内存量,实质上我们已经在使用那个RAM了。所以收费是收取的使用CPU和RAM的费用。我们在考虑把这两种费用分离出来,这样我们就可以继续charge CPU-hours,然后也可以charge instance-hours(这个不能叫做RAM-hours)。这些都看起来越来越使人迷惑并且这么做也不会更便宜,因此看起来并不太值得去这么做。然而我知道已经有很多关于用这种收费的讨论。无论你把它称之为RAM-hours 或者instance-hours,也不论你是否在顶层为CPU-hours 收费,最后的结果都是一样。对应用程序会根据对其分配的内存量和分配的时间而收取费用。这意味着那些想省钱的应用程序有必要在RAM-hours方面做优化,这在本质上意味着用更少的时间来完成任务。
多任务的回归,宝贝
基于价格的实例,其目标是能尽可能多地利用实例。这需要多线程,因此在容器中可以尽可能多的去执行仿真进程。之前的GAE都是单线程。启动更多的实例是为了处理更多的请求。这显然并不高效,所以我们重新写线程代码,这是实际上是一种很好的方式。启动一个巨大的JVM就是我们为什么要把应用服务器放在首位而远离CGI模型的原因。GAE模型并不盈利是其一点小小的遗憾。
多线程方法的收益很高,以至于GAE指望它们来平衡提高的成本。Brandon Wirtz说:
我刚刚完成了对我的应用程序早期版本的重新编写(从Python到Java)。这不是我最新的app版本,但是这类似于一个已经部署了数月的版本。所有的版本都在做相同的事情,能够兼容各种方式。我还没有运行那个版本太久,但是我已经从20个实例减到1个实例了。当有足够的数据来确认的话,我会在8小时之内给出一个完整的报告。
我完全相信,这个app的规模,将会是整个应用程序规模的一个重要指标。(这次重新编写花费了三个小时的时间,几乎是一句句进行对照编写的)。
内存消耗会随着并发和多线程的应用而提升,因此看到它们如何协同工作讲会是一件很有意思的事情。
对于仅在RAM的基础上运行的服务进行比较。RAM是指示利用服务来完成任务的诸多因素之一。APP Engine 还包括许多免费的API,不需要管理APP,也不需要运行维护OS等。APP Engine是一个平台,当我们决定使用不同的资源(电子和人力资源)时,那么收费也将有所不同。
当比较价格时,千万不要忘记人力资源的数据存储,可扩展前端,memcache,以及管理这些东西的开销。我曾经管理过分布式的数据库,如果你还没有这么做,那么它比你想象的更有考虑的价值(假设你关心你的数据)。不要忘记管理成本的开销,即使一切运行正常的话,一年也得有几千美元的开销。
对于什么是有价值的,我并不认为拿一个GAE实例比较一个像VPS的实例是公平的。
它们是非常不同的’beasts’.理论上GAE提供更多的东西。Google处理所有的安装、配置以及负载均衡等。
如果仅仅使用相当于十分之一的VPS,那么这就显得有点昂贵。但是一旦你开始需要管理多个VPS,提供负载均衡器,重新提供故障情况等进行备份。所有出现的这种情况均与GAE有关。
所以不要忘记获取一个免费的实例配额。
后端服务是昂贵的
Ugorji:
后端的instances看起来貌似是荒唐的且价格过高的(对于一个256MB/1.2GHZ的Instance来说,每月需要花费115美元)。它们这种过高的价格使得它们对于许多那种可能因为此功能而举债的那些用户而言,是毫无吸引力的,这就造成许多用户去寻找其它的产品。
在某种程度上,貌似我们到了进退不得,左右为难的地步。后端其实是应对那种需要长时间运行且频繁占用CPU的活动的好办法,它可以使我们从那些任务链的当前业务中解放出来,其中每个任务都是在一个固定的时间内完成,或者使用map-reduce操作。然而,后端是如此的昂贵,以至于大部分人都不会去使用它。不幸的是,当前使用前段的instances和task/map-reduce的业务也是如此地昂贵,这是因为我们不得不为超出我们使用的部分额外支付1/4 instance小时税。
FAQ for out of preview pricing changes:
因此,在延时和每个instance每秒可处理的请求数量之间存在这一种直接的关系,举例来说:10ms latency = 100 request/second/instance,100ms latency = 10 request/second/Instance,等等。多线程的instances可以处理许多并发的请求。因此,在CPU消耗和每秒请求数之间也存在一个直接的关系。举例来说,对于一个B4(大约2.4GHZ)instance:消耗10 Mcycles/request = 240 request/second/Instance,100 Mcycles/request = 24 request/second/Instance,等等。这些数字是理想的情况下的,但是它们应该同你能够在一个instance上完成的量十分接近。多线程的instances当前只支持Java,我们计划今年晚些时候支持Python。
由于Google所做的特定的设计决策,高延时请求并不会扩充*on appengine* 。高延时请求在其它平台上扩展的很好——运行Node.js/Tornado/EventMachine等等的分支在应对上万个l延时请求方面毫无问题。甚至传统的java appservers在可接受的限制下处理延时——取决于你正在做什么,使得你可以在每个JBoss instance上应对成百上千个并发请求。
GAE 无法再支持以广告为收入来源的应用
Kaan Soral:
比如说我现在有一个依靠广告收入的应用。并且假设每个请求耗时1秒,任务调度器没有任何问题。因此,我每小时也就是3600秒为一个instance支付$0.05 。因此让我们把那个数字平均到3600个request,并且假设有1800个page views(假设用Ajax做的)。因此1000个page views的开销是:$0.05/1800*1000=0.027$。假如一切没有问题,而且不把后端任务计算在内,尽管我的十分大,我至少需要 0.027$ ecpm。举例来说,土耳其的流量有时ecpms可能会低于0.1$,而且我确定肯定还有其它国家的ecpms有着更低的ecpms,我们的流量费是最佳的。总结一下,看起来如果我使用GAE,貌似我一直会担有开销比收入高的风险……
我若在一个专用服务器上部署应用,通常一个服务器是几乎空闲的,负载基本上是0.5(8个核),有时候是2-3,并且我确定我没有使用它们优化到%20,但是我的成本仍然是收入%10!如果我可以使用一个服务器到最大级,可能达到成本只占%2。在最好的情况下,假设没有任何问题的情况,看起来在GAE上这个比率是%25。
这可能预示着对于移动服务来说,如果想采用GAE作为移动客户端的便宜后端的话看起来并不可行。
或者说是通过云端集成—我希望更多的人通过GAE的用户帐户/认证,把他们的文件存放在一个或更多个CDN上,使用第三方pub-sub服务更新客户机,可能的话将不同服务间的数据(热数据vs引用数据)集成起来,为那些不会遭受流量激增的后台进程保持固定的专用实例等。我希望能够实现抽象服务—能够用于编写完成一种服务的API,并且独立于任何具体平台的库。
Python or Java?
Java 具有即时编译技术JIT,因此假设实例保持足够长的时间使即时编译生效,并假设具有更高的延迟处罚,那么在GAE上,java会比python更受欢迎吗
整个实例的代价计算太复杂
Daniel Florey关于这一切的复杂度的有很好的见解:
有没有一种方法,可以在不必了解程序调度引擎内部的前提下,建立一种简单的代价模型?我认为为消耗的资源付出合理的代价是可以的,但是对于实例/小时的方法,并不认同。这让我感觉像是impl在为我负责。我希望有一种简单的方式(从用户的角度),可以由我负责cpu资源与内存使用的代价,可以对“可扩展性/处理能力”进行预算处理,使程序引擎负责它需要负责的一切,并可以根据设置加速/减缓我的程序。
相关资料
翻译:李凯、曾怀东、王鑫、朱翊然、靳彬、林业、马少兵
Linux 内核枚举并跟踪其所有的内存,且对于绝大部分的内存,它都可以单独的寻址到每一个字节。transcendent memory (“tmem”)为内核提供更好的利用内存的能力,使其不用再去枚举内存,在某些情况下甚至不用再去跟踪或者不再用去直接去寻址了。对于内核开发者来说,这听起来可能跟他们的直觉相违背甚至是愚蠢的,但是我们将看到其确实是很有用处的;实际上它给内核增加了一个提高灵活性的中间层,这样基于一些微小的内核变化之上,就能够实现一些较复杂的功能。最终的目标是使得内核可以更有效的利用内存,多个内核之间(包括虚拟化环境和非虚拟化环境)实现负载均衡,以期使得单个系统(甚至跨数据中心)可以达到更好的性能更低的RAM开销。这篇文章对transcendent memory 进行概述以及说明这种技术是怎样在Linux内核中运用的。
【编译者注:如果仅有“地址枚举并直接访问”这一种内存使用模式,那么显然多个虚拟机使用内存就太不灵活了】
内核与tmem是怎样展开对话的,将在第二部分进行详细的描述。内核管理着适用于 tmem 的若干不同类别的数据。其中"clean pagecache pages" 和 "swap pages"是内核开发者所熟知的两种。处理前者的补丁叫做“cleancache”它已经被并入3.0kernel里面了。处理交换页的补丁是frontswap,现在linux 内核邮件列表中仍然有对其进行审查。可能还有其它类别的数据与tmem能够更好的协同工作。这些对于tmem来说合适的数据源统称为“frontends”,我们将在第三部分详细的介绍。
tmem使用不同的方法存储数据。对于tmem来说这些实现方式称为“backends”,任一前端都可以应用任一后端(可能使用shim连接它们)。最初的tmem应用是我们所熟知的“Xen tmem”,它允许 Xen hypervisor 的内存为一个或者多个支持tmem的 guest 使用。Xen tmem已经应用在Xen中两年了,从Xen4.0开始的;内核里的shim已经并入3.0版本里了。另一个Xen驱动部件,Xen self-ballooning 驱动,用来支持guest内核更有效的使用tmem,已经并入3.1版本里了,同时也包括“frontswap-selfshrinker”,查看本文最后的附录以了解这部分更多的内容。
Tmem的第二个应用并不是虚拟化,而是“zcache”,它是内核里面的一种驱动,用来存储压缩页。这其实就是“倍增内存”的方法,对任何能通过tmem前端(例如cleancache, frontswap)使用的内存都能应用,从而减少内存的需求,例如嵌入式内核。Zchache作为staging驱动被合并到在2.6.39版本中。
Tmem的第三个应用正在实施,称为“RAMster”.在RAMster中,一些“closely-connected”(【编译者注:极高带宽、极低延时的机器之间的互连】)的内核可以有效地共用它们的RAM,这样的话对于一台缺少RAM利用的机器来说可以利用另一台机器上闲置的RAM。RAMster也被称为“peer-to-peer transcendent memory”,通常应用在物理系统之间,但是也可以虚拟机内核进行测试。RAMster最适合用于高速‘exofabric’连接的多系统环境里,在这个环境里,一个系统可以直接寻址到另一个系统内存,其最初的原型是建立在以太网的连接上。
还有一些其他的tmem实现也被提出:例如,在tmem可能会在何种程度上帮助KVM和/或容器(container)方面发生了一些讨论,随着最近zcache的更改被合并入3.1,部署必要的shims并尝试这些变得很容易;但还没有人加紧做这件事情。另一个例子是,tmem协议可能适用于某些种类的RAM的技术,如“"phase-change”内存(PRAM);这些技术大多具有某种特性,例如有限的写周期,它们可以通过tmem一类的软件接口被有效管理。在一些RAM技术厂商之间已经开始了对此的讨论。还有一个例子是 RAMster的变种:集群中的单台主机作为“内存服务器”并且只在这台主机上增加内存;这些内存可能是RAM,或者是类 RAM 的东东,比如 fast SSD。
现有的tmem实现和一些未来实现的设想将在第四部分进行介绍。内核通过一个精心定义的接口同tmem进行通信,它被设计成向tmem的部署提供最大限度灵活性同时把对内核的影响降到最低。tmem接口可能会显得奇怪,但也有其特殊性很好的理由。请注意在某些情况下tmem接口完全是和内核交互,因此它是“API”;在另一些情况下它定义了两个独立软件组件之间的边界(例如,Xen和一个guest Linux kernel),所以它被称为“ABI”更合适。
(泛泛而读的读者不妨跳过这节)
Tmem应当被视作“拥有”一些内存的“实体”。这个实体可能是 in-kernel driver,其他内核,或者hypervisor/host。前面已经提到过,tmem不能被内核枚举;内核不知道tmem的大小,tmem可能动态改变,也可能在任意时刻变“满”。因此,对每一个页面请求内核必须“询问”tmem来接受数据或检索数据。
Tmem不是字节寻址的 —— 只是大段的数据(准确或大约为一个页面的大小)在内核内存和tmem之间进行拷贝。由于内核无法“看到”tmem,API/ABI的tmem侧负责将数据拷贝进/出内核内存。tmem把相关的数据块放入一个池来管理;在池中,内核选择一个唯一的“句柄”来代表数据块的地址。当内核请求创建池的时候,它会指定一些特定属性(这些属性下面会讲到)。如果池创建成功,tmem提供一个“池id”。句柄在同一个池内是唯一的,但是在不同的池之间不是唯一,句柄由192位“对象id”和32位的“索引”组成。大致上,一个对象相当于一个“文件“,索引相当于文件中页的偏移量。
tmem两个基本操作是”put”和“get”。如果内核希望在tmem中保存数据,它应该使用“put”操作,提供一个池id,一个句柄以及数据的位置;如果put操作返回成功,tmem就复制了数据。如果内核希望获取数据,它应该使用“get”操作,提供池id,句柄,以及位置用于tmem放置数据;如果get成功,返回的数据会被放置在指定的位置。请注意,不像I/O,tmem的拷贝操作是完全同步的。As a result, arbitrary locks can (and, to avoid races, often should!) be held by the caller.
有两种基本池类型:短暂型和持久型。成功存入短暂型池的页面在内核使用对应的句柄进行后续get操作后,可能会存在也可能消失。成功存入持久型池的页面能够保证在后续get操作后依然存在。(此外,池可能是“共享的”或是“私有的”)。
内核负责维护tmem数据及内核自己的数据之间的一致性,tmem有两种“刷新”操作来协助保持一致性:为了分离一个句柄和其他tmem数据,内核使用“刷新”操作。为了分离一个对象和对象中的所有数据块,内核使用“刷新对象”操作。在刷新之后,后续的get操作会失败。在(非共享的)短暂型池上的get操作是破坏性的,例如,暗含了刷新操作;否则,get是不具有破坏性的并且需要明确的刷新。(附录B中描述了两个附加的一致性保证)尽管还有其它的前端,frontswap和cleancache这两个现有的tmem前端包含了内核内存的主要类型中的两种,这两种对内存压力都很敏感。这两个前端属于互补的:cleancache处理(clean)那些已映射的页面(编译者注:VFS disk cache page),否则那些页面将会被内核回收;frontswap处理(dirty)那些匿名页,否则这些页面将被内核换出。当一个成功的cleancache_get发生时,会避免一次硬盘读。当一个成功的frontswap_put(或get)发生时,则会避免一次swap设备写(或读)。同时,假设tmem比硬盘的paging/swapping都要快得多,那么将会从一个限制在内存中的环境中获得客观的性能提升。
在一个Linux系统中,“虚拟内存”的总量是物理RAM加上所有已配置的swap设备的量之和。当有一个工作量超过物理RAM的大小的“工作集”时,就会发生swapping —— swap设备本质上是用来模仿物理RAM的。但是通常情况下,一个swap设备要比RAM慢上好几阶,因此swapping已经变成了和可怕的性能相同的词语了。结果,聪明的系统管理员会增加物理RAM或者重新分配工作量来保证尽可能地避免swapping。但是如果swapping并不总是那么慢又会怎么样呢?
Frontswap允许Linux的swap子系统使用 transcendent memory,当有可用的内存的时候,会取代往一个swap设备发送数据或从一个swap设备获得数据。Frontswap本身并不是一个swap设备,也因此它并不要求像swap设备那种的配置。它并没有改变系统中总的虚拟内存的数量,它只是导致了更快的swapping...一些或大多数或几乎所有时候,但并不总是如此。记住, transcendent memory的数量是不可知的和动态变化的。使用frontswap,当一个页面需要被换出,swap子系统会问tmem它是否愿意接收这个页的数据。如果tmem拒绝,swap子系统会像往常一样向swap设备中写这个页。如果tmem接受,swap子系统可以在任何时候请求此数据页,并且tmem保证了数据的可取回。过一会儿,如果swap子系统确信数据不再有效时(比如持有此数据的进程已经退出),它能够将数据页从tmem中flush掉。
注意,tmem可以拒绝任何frontswap的“put”。为什么这样呢?一个例子就是如果tmem是多个内核的共享资源(又称之为“clients”),就好像Xen tmem或者RAMster的情况;另一个内核可能已经声明了这个空间,或者可能这个内核超过了tmem所管理的限额。另一个例子是,如果tmem在压缩数据,就像zcache中做的那样,并且它认为压缩的数据页太大了,在这种情况下,tmem可能会拒绝掉没有充分压缩的或者甚至如果平均压缩率增大到不可接受的的页面。
Frontswap的补丁集是一种非侵略性的,当frontswap被禁止掉的时候,它一点都不会影响swap子系统的行为。事实上,一个关键的内核维护者观察到,frontswap看起来是同swap子系统紧密结合在一起的。这是一件好事,因为现在的swap子系统的代码是非常稳定的,而且并不经常使用(因为swapping是如此之慢),但仍然是系统正确性的关键;对swap子系统的巨大改变可能并不明智,frontswap只是修改了它的边缘。
一些实现的注意点:Frontswap要求开启swap的情况下每页1 bit的metadata。(Linux swap子系统直到最近要求16bits,现在要求每页8bits的metadata,因此frontswap增加了12.5%)这每页的1 bit记录了这个页面是在tmem还是在物理swap设备。因为,任何时候,可能一些页在frontswap中,另一些在物理设备上,swap子系统“swapoff”代码也要求做一些修改。并且因为使用tmem比swap设备空间更有价值,frontswap提供了一些额外的修改来达到可以执行“临时的swapoff”。当然,hooks在read-page和write-page中传输数据到tmem中,并且添加了一个hook用来当数据不再需要时可以被flush掉。补丁部分影响核心的内核组件合计少于100行。在大部分的工作负载下,内核从慢速的磁盘中取到页,当RAM还有足够的空间时,内核会在内存中保持大部分页的备份,因为假设磁盘中的页使用过一次就很可能会再次使用。当发生两次磁盘读写而又有足够的空闲RAM没有使用的情况是没有意义的。如果在它们当中的一页中写入任何数据,这么变化必须要写回磁盘,但是预期到未来的变化,页(清理过的)会继续保持在内存中。其结果是,在“页缓存”中的清洁页的数量频繁的增长而填满了绝大多数的内存。最终,当内存几乎被填满,或者如果工作量增大而需要更多的内存的时候,内核会“回收”一部分这样的清洁页,数据会被丢弃,页面可以被别的东西利用。没有数据会丢失,因为内存中的清洁页与磁盘中的相同的页面是一致的。然而,如果内核随后决定它确实需要那个页面的数据,它必须再次从磁盘中获取,这种情况叫做“refault”。由于内核不能够预期未来,一些被保持的页再也不会被用到,而一些被回收的页会很快的被“refault”。
cleancache 允许 tmem 存储少数 rerault 时产生的清洁页缓存页面。当内核回收一个页,而不是丢弃该页面的数据,它把数据放入 tmem 中,标记为 “ephemeral”,这意味着当 tmem 关闭时页的数据可能被丢弃。随后,如果内核决定需要该页的数据,它会要求 tmem 返还此数据。如果 tmem 保留该页,它会返回此数据,否则,内核继续 refault 操作,像平常一样从磁盘中取回数据。
为了正确的运行,cleancache的“hooks”被放置在页面被回收以及refault操作发生的地方。内核也必须要确保页缓存、磁盘以及tmem间的相干性,所以该hook也会出现在内核使数据无效的地方。由于cleancache会影响内核的VFS层,并且不是所有的文件系统使用到VSF的全部特性,文件系统必须选择是否使用cleancache当它挂载一个文件系统时。
cleancache有一个有趣的地方:clean pages 可能会保存在tmem中但是在内核的页缓存中已经没有空闲的页面。因此内核必须为页面提供一个在整个文件系统中独一无二的名字(“句柄”)。在一些文件系统中,inode 节点号已经足够了,但是在现代的文件系统中,使用的是192位的“exportfs”的句柄。一个常见的问题是:用户空间的代码是否可以使用 tmem ?例如,规避页缓存的企业应用是否使用 tmem。当前,答案是否定的,但我们可以通过实现“超内存”系统调用,来实现它。这样可能会产生一致性问题,能否在用户空间中解决这些一致性问题,还有待于研究。
其它的内核应用是怎样的呢?有人提出,内核的 dcache 可以会为 tmem 提供一个有用的数据源。这也需要进一步的研究。tmem 技术的接口允许多个前端运行在不同的后端之上。尽管将来可能会允许某种形式的层次结构的出现,然而当前,只可以设定一个后端。tmem 技术的后端拥有一些共同特征:一个 tmem 技术后端类似于一块阻塞设备,但它不执行任何I/O,也不调用任何阻塞I/O子系统。事实上,tmem 技术的后端的功能完全是同步的,即在它运行期间,不能进入休眠状态,也不能调用调度程序。当内核中一页的数据被复制后,一个“PUT”完成。当一页数据被复制到内核的数据页时,一个“GET”成功完成。当这些限制对 tmem 技术后端造成一些困难时,他们仍然会保证后端满足“超内存”技术接口的要求,同时对核心内核做出最少的修改。
尽管 tmem 被认为是一种在一组内存需求经常变化的客户机之间共享固定资源的方式,同时,在被一个单独内核用于存储N页数据的RAM容量小于N*PAGESIZE,并且这些数据只能以页的粒度进行访问时,也可以很好的工作。Zcache 同时包括了 tmem 实现和内存压缩,以减少 tmem 前端数据的空间需求。因此,在内存用量紧张时,Zcache 可以充分增加RAM中清理缓存与交换缓存的页数,以显著减少磁盘I/O的次数。
Zcache 当前还是一个开发中的驱动,因此它是可变的;Zcache 可以同时处理持久页(来自于frontswap)与临时页(来自于cleancache),且这两种情况下,它都使用内核中的lzo1x程序压缩/解压缩页中的数据。用于持久页的空间是通过xvmalloc 片,开发中的ZRAM驱动中一个用于存储压缩页的内存分配器获得的。用于临时页的空间是通过内核调用get_free_page()获得的,然后使用一种称之为“compression buddies”的算法对压缩的临时页进行配对。这个算法保证了包含两个压缩的临时页的物理页框,在必要时能够顺利的回收。Zcache 提供了一种收缩策略,以便于那些能够被回收的页框,在需要回收时,由内核使用已存在的内核收缩机制。
Zcache 很好的证明了 tmem 技术的可伸缩性特征之一:回想下,通常情况下数据可以很好的压缩(两种或多种情况之一),但仍然可能会产生没法很好地压缩的长序列数据。由于 tmem 技术在“put”的时候,可以拒绝任何页,因此Zcache策略可以避免存储这种压缩的不好的数据,而把它交给原始交换设备进行存储,以动态优化存储在RAM中的页的密度。
RAMster 仍然在开发中,但概念已经被验证。RAMster 假定系统之间拥有高速互联,专业说法是 "exofabric"。每台机器中都有部分内存被收集起来通过 tmem 做共享资源使用。集群中的每个节点既是 tmem 客户端也是服务端,每个节点可独立配置拿出多少 RAM 做共享。Thus RAMster is a "peer-to-peer" implementation of tmem
理论上这有点像远程同步DMA,让一个系统去读/写另一个系统的RAM。最初的RAMster概念验证中使用的是一个标准的以太网连接。exofabric 传输速率远高于磁盘读写的速度,肯定能从中得到额外好处。
有趣的是,RAMster-POC(RAMster概念验证)展示了tmem的一个有用的因素:一旦页面被置入tmem,在需要的时候,只要页面可以被重组,数据就可以以多种多样的方式转换。当页面被应用于RAMster-POC,他们首先被压缩并且使用一个zcache-like tmem backend来本地缓存。随着本地内存限制增加,一个异步的进程会尝试“remotify”页面到集群中另一个节点;即使该节点拒绝了这次尝试,只要本地节点能够跟踪到远程数据所在的位置,还可以尝试其它节点。尽管当前的RAMster-POC 无法实现这一点,但可以remotify很多份从而实现系统更高的可用性(例如,从节点故障中还原)。
虽然RAMster中这种多层次机制在puts方面很好用,但当前针对gets并没有同样好用的机制。当一个tmem前端需要一个稳定的get时,数据必须被迅速且异步的获取到;请求数据的线程必须处于忙等待状态,并且调度程序没有被调用。因此现有的RAMster-POC对多核处理器是最合适的,其不寻常的机制可以使所有内核都同时处于激活状态。当一个系统运行一段时间后,通常内存会被 clean pagecache 所占用。而那些使用tmem机制的系统,尤其是 xen,把页面放在 tmem 而不是 guest 内存中会很有意义。为了实现这个功能,xen实现了具有破坏性的“自我膨胀”。通过操作 xen ballon driver 来人工地创建内存压力,以回收页帧,从而强迫内核将页面发送到 tmem 。The algorithm essentially uses control theory to drive towards a memory target that approximates the current "working set" of the workload using the "Committed_AS" kernel variable. Since Committed_AS doesn't account for clean, mapped pages, these pages end up residing in Xen tmem where, queueing theory assures us, Xen can manage the pages more efficiently. 【编译者注:不太理解意义何在,可能和避免 OOM 有关系?】
如果工作集的增长速度出乎意料的快,超过了 self-balloon driver ,就需要提供可用的ram,交换页面。但是在大多数情况下,frontswap尽可能将那些交换页面进入到xen的tmem。然而实际上,内核交换子系统保证所有的交换在磁盘上发生,交换页面将保存在磁盘上好长时间,尽管内核知道这些页面可能不会在被使用。这样做的原因是因为磁盘成本低廉且可以重复写。假设这些页面放在frontswap上,将会占据很多有用的空间。
Frontswap-自我压缩技术用于解决这个问题:当frontswap活动比较稳健,以及客户机内核返回了一个状态,说明目前没有内存压力,根据这个压力删除在frontswap中的一些页面,使用一个叫”partial”的swapoff接口,返回信息给内核内存,来根据需要来释放tmem空间以供紧急需要。例如其他的客户机正处在内存饥渴态。
Appendix B: Subtle tmem implementation requirements
Although tmem places most coherency responsibility on its clients, a tmem backend itself must enforce two coherency requirements. These are called "get-get" coherency and "put-put-get" coherency. For the former, a tmem backend guarantees that if a get fails, a subsequent get to the same handle will also fail (unless, of course, there is an intermediate put). For the latter, if a put places data "A" into tmem and a subsequent put with the same handle places data "B" into tmem, a subsequent "get" must never return "A".
This second coherency requirement results in an unusual corner-case which affects the API/ABI specification: If a put with a handle "X" of data "A" is accepted, and then a subsequent put is done to handle "X" with data "B", this is referred to as a "duplicate put". In this case, the API/ABI allows the backend implementation two options, and the frontend must be prepared for either: (1) if the duplicate put is accepted, the backend replaces data "A" with data "B" and success is returned and (2) the duplicate put may be failed, and the backend must flush the data associated with "X" so that a subsequent get will fail. This is the only case where a persistent get of a previously accepted put may fail; fortunately in this case the frontend has the new data "B" which would have overwritten the old data "A" anyway.
翻译:王鑫、朱翊然、李凯、曾怀东、马少兵、林业
时间:2010/09/28
原文地址
The “swap insanity” problem, in brief
在一台包括了2个4核CPU,64GB内存的服务器上,给 MySQL 配置了 48GB 之巨的 InnoDB 缓冲,随着时间的推移,尽管观察到的数据(见最后注1)表示并没有真正的内存压力,Linux 也会把大量的内存交换到磁盘上。通过监控发现,配置的内存超过了实际所需,而且也不存在内存泄漏,mysqld的RSS占用正常且稳定。
通常来说,少量的交换没有什么问题。但在许多情况下,真正有用的内存,尤其是InnoDB缓冲池的主要部分,会被换出。当它再一次被需要时,又会花费很大的性能将它换进,在随机的查询会引起随机的延迟。这可能会在运行系统上造成整体的性能不可预测性,而且一旦开始进行交换,系统可能就会进入性能的“死亡螺旋”。
虽然不是每个系统,或者每个工作负载都会经历这个问题,但是它已经足够普通以至于众所周知,而对于那些十分了解它的人来说,它可能会是一个最主要的麻烦。
The history of “swap insanity”
在过去的二到四年间,已经有过许多关于关闭还是开启Linux swapping和MySQL的讨论,这些总被称为“swap insanity”(我认为这是由Kevin Burton创造的)。我紧密关注这些话题,但是我并没有为此贡献很多,因为我没有添加任何新的东西。在过去的几年间,对此讨论作出主要贡献的是:
尽管有这么多的这论,但是并没有带来太多的改变。有一些类似于“黑客式”的解决方法来使得MySQL停止交换,但是什么都不能确定。我已经了解这些解决方案和黑客式的手法一阵子了,但是核心的问题从来没有解决:“为什么会发生这?”还有它从来不适合我。我最近尝试去理顺这个问题,希望能够一劳永逸地解决它。因此到目前为止我做了大量关于这个问题的研究和测试。我学到了很多,我认为写一篇博客可能是会分享它的最佳途径。希望大家喜欢。
从几年前,已经有许多讨论和一些工作进入了加入相对较新的交换方法的调整的方面,我认为那可能已经解决了一些原始问题,但是此刻,机器的基础架构已经变为了NUMA,我认为这引入了一些新的问题,这些问题有着极为相似的症状,并且掩去了原始问题修订的成功。
对比SMP/UMA和NUMA两种架构
The SMP/UMA architecture
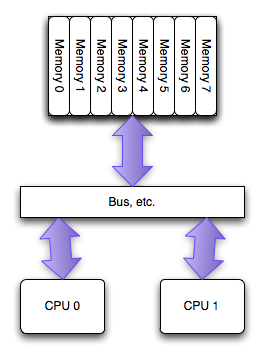
当PC领域最初拥有多处理器时,它们能够机会均等的进入系统中的所有内存。这叫做对称多处理器(SMP), 或者有时候叫统一访存架构(UMA,特意和NUMA进行对比)。在过去的几年中,每个 socket 上的单个处理器之间访问内存已经不再使用这种架构,但是在每一个处理器的多个核之间仍然盛行:所有的内核拥有均等的进入内存的机会。
The NUMA architecture
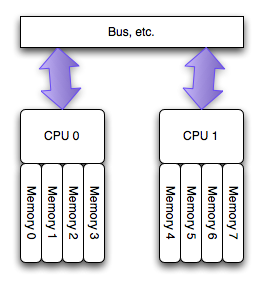
运行在 AMD Opteron 和 Inter Nehalem 处理器(见注2)上的多处理器的新的架构,叫做非匀称访存架构(NUMA),更确切的说是一致性缓存非匀称存储访问架构(ccMUMA)。在该架构中,每个处理器拥有一个“本地的”存储体,使用它可以较快的访问(延迟小)。整个的系统仍旧可以以整体的形式运行,从任何地方访问所有的内存,但是这样有潜在的高延迟和低性能的可能。
从根本上来说,“本地”的那些内存访问会快些,也就是说,可以比其他的地址(“远程”的和其他处理器关联的那些)以更小的代价访问。如果想得到更详细的关于NUMA实现的讨论以及它在Linux的支持,请去lwn.net上看 Ulrich Drepper 的文章。
How Linux handles a NUMA system
当运行在NUMA架构系统上时,Linux会自动的知道这个事实,并且做以下的事情:
你可以用numactl --hardware命令查看linux是怎么枚举你系统上NUMA的布局
# numactl --hardware available: 2 nodes (0-1) node 0 size: 32276 MB node 0 free: 26856 MB node 1 size: 32320 MB node 1 free: 26897 MB node distances: node 0 1 0: 10 21 1: 21 10
输出结果里讲了这么几件事情:
NUMA是如何改变 Linux 工作模式的
从技术层面来说,只要一切运行良好,UMA或者NUMA是没有理由在OS水平级上去改变运行方式。然而,如果要获得最好的性能,那么需要要做一些额外的工作,直接去处理NUMA底层的一些事情。如果把CPU和内存当作一个黑盒子,那么linux会做以下一些意想不到的事情:
使用numactl这样非常简单的程序,使得任何进程的NUMA策略都是可以改变的,具有广泛深远的影响。除此还能做些额外的工作,即通过链接到libnuma并写一些代码去管理策略,可以使其在细节上做些微调。简单的应用numactl已经可以做一些有趣的事情:
What NUMA means for MySQL and InnoDB
InnoDB以及其他所有数据库服务器( 包括 Oracle 在内),对linux来说都表现为非典型的工作负载(以大多数程序的角度):一个单一庞大的多线程进程消耗了系统几乎所有的内存,并且将会不断消耗系统剩余资源。
在基于NUMA的系统中,内存被分配到各个节点,系统如何处理这点不是那么简单。系统的默认行为是为进程运行所在的同一个节点分配内存,这种方式在内存量比较少的情况下效果不错,但是当你希望分配超过半数的系统内存时,这种方式即便只应用于单一NUMA节点,在物理层面上也变得不再可行:在双节点系统,每个节点中只有50%的内存。另外,由于大量不同的查询操作会同时运行在两个处理器上,任何一个单独的处理器都无法优先获取特定查询所需的那部分特定内存。
这显然非常重要。使用 /proc/pid/numa_maps 我们可以看到所有mysqld做的分配操作,还有一些关于它们的有意思的信息。如果你进行大量的查找,anon=size,你可以轻易的发现缓存池(它会消耗超过51GB的内存,超过了设置的48GB)
2aaaaad3e000 default anon=13240527 dirty=13223315 swapcache=3440324 active=13202235 N0=7865429 N1=5375098
显示的各字段如下:
整个numa_maps可以用一个简单的脚本 numa-maps-summary.pl 进行快速的总结,这个脚本是我自己编写用于分析这个问题的:
N0 : 7983584 ( 30.45 GB) N1 : 5440464 ( 20.75 GB) active : 13406601 ( 51.14 GB) anon : 13422697 ( 51.20 GB) dirty : 13407242 ( 51.14 GB) mapmax : 977 ( 0.00 GB) mapped : 1377 ( 0.01 GB) swapcache : 3619780 ( 13.81 GB)
我发现了两件有趣并出乎意料的事情:
下图显示的是MySQL数据库的内存分配图:
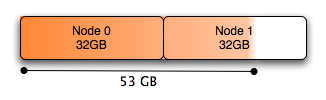
总体来说,Node 0几乎完全耗尽了空闲的内存,尽管系统有大量的空闲内存(将近有10G用于缓存)给Node 1.如果位于Node 0上的进程调度需要大量的本地内存的话,就会导致已经分配了任务的内存被交换,以满足一些Node 0页面的需要。尽管Node 1上存在大量的内存,但是在许多情况下(对这点,到现在我还不理解,见注3),Linux系统内核宁愿将Node 0上已分配任务的内存交换,也不愿使用Node 1上空闲的内存容量。因为页面调度远远比本地内存处理花销更大。
小变化,大效果
上述问题最容易的解决方案是交叉分配内存,运行:
# numactl –interleave all command
我们可以凭借将脚本mysqld_safe.sh只改动一行,在脚本中添加(cmd="$NOHUP_NICENESS"),使得在启动mysql命令前,启动numactl命令。该脚本为已添加(cmd="$NOHUP_NICENESS")命为的内容:
修改配置后,会发现当MySQL需要内存得时候,它将采用交叉分配的方式,给所有节点进行分配,使得每个节点都承载有效平衡的内存分配。同时也会在每个节点上留下一些空闲的内存空间,允许Linux内核在两个节点之间缓存数据,这种方式仅仅释放缓存的时候(当支持这种情况的时候工作),才允许任何一点节点内存容易释放,而不是页面调度的时候。
通过性能回归测试,我们已比较了两种情况下的性能,使用DBT2标准检测程序(本地内存+溢出内存----交叉内存),最终发现:在一般情况下的性能是等同的,这是可以预料的。突破发生在下面情况:使用交换的所有案例,在重复使用的情况下,系统不再发生交换。
你会看到所有采用numa_maps(NUMA: 非一致内存访问)分配的内存平均分布在Node 0和1上:
2aaaaad3e000 interleave=0-1 anon=13359067 dirty=13359067 N0=6679535 N1=6679532
And the summary looks like this:
N0 : 6814756 ( 26.00 GB) N1 : 6816444 ( 26.00 GB) anon : 13629853 ( 51.99 GB) dirty : 13629853 ( 51.99 GB) mapmax : 296 ( 0.00 GB) mapped : 1384 ( 0.01 GB)
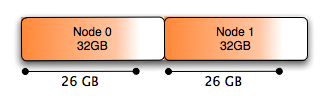
图形表示就是这样
关于 zone_reclaim_mode 的一些题外话
配置 /proc/sys/vm 中的 zone_reclaim_mode 可以用来调整 NUMA 系统的内存回收策略。从 linux-mm 列表中的一些讨论表明,该配置对本例子不会改善。
一个更好的解决方案?
我觉得(也得到了linux-mm邮件列表的支持)一定还有更大的优化空间。尽管至今为止我任何的测试都没做。交错化分配是一个方法,如果它真的解决了这个问题的话,我想一个更好的方案就是,使用 libnuma 智能化对待 NUMA 架构。下边是一些涌现出来的想法:
我不知道以上的想法是否有哪些真的可以在一个真实系统中展现出特别优点,但是我很希望能得到评论或者其它的观点。
====== 这是华丽丽的分割线 =========
July 20, 2011
This article was contributed by Josh Berkus
Data Warehousing
翻译:马少兵、曾怀东、朱翊然
尽管服务器存储、处理能力得到有效的提高,以及服务器价格的降低,让人们能够负担起大量的服务器,但是商业软件应用和监控工具快速的增加,还是使得人们被大量的数据所困扰。在数据仓库领域中的许多系统管理员、应用开发者,以及初级数据库管理员发现,他们正在处理“海量数据”-不管你准备与否-都会有好多不熟悉的术语,概念或工具。已知该领域大约有40多年的历史,广为人知。这篇文章ss对那些想去了解该领域的人来说是一个起点。
什么是数据仓库呢?
数据仓库不等同于“海量数据”;恰恰相反,而是其子集。海量数据也包含:通过大量的连接提供每秒百万次服务请求的系统,例如Amazon的Dynamo database。数据仓库一般指的是:在相当长的时间内堆积数据,仅仅需要处理大量数据请求中的少部分的系统。
数据仓库真正的答案之一:三种不同的问题--组织归档,数据挖掘或分析。有时它回答了三个结合。
“我想在相当长的时间内存储大量数据,可能对其从不进行任何查询服务”。
由于HIPAA法案、奥克利斯法案、第8公司法以及其他相关法律,归档成为非常流行(或者、至少、必须)的一种数据。它也被叫做“WORN” (写数据后,从不去读) 数据。公司积累了大量他们不想要的数据,但是却不能扔掉,从理论上来说,数据需要在合理的时间内要去访问。存储的大小范围从GB到TB。
这种归档系统其中一个非常好的例子是:我帮Comptel and Sun Microsystems建造的关于欧洲手机呼叫完成数据。每个城市呼叫完成数据大小为75TB,可以预料,每周每一个数据库应至少应答一条信息请求。这就允许我们使用非常便宜的PostgreSQL数据库、Solaris和压缩文件系统的组合。
如果你想建立一个文档服务器,你仅仅的需求是:花费最少的存储成本和确保文档服务器和当前数据同步。一般地,这意味着需要对数据进行压缩、以及一个能够稳定工作非常廉价的硬盘驱动器的数据库或者是磁带库。查询的速度和其他特性不是关心的事情。有趣的是,这是数据库的一种类型,但是却没有很好的开源解决方案。
“我一天堆积了1GB的数据,知道其中有有用的信息,但是不知道那些是。”
数据挖掘是数据仓库中一种非常普遍的类型;大多数的公司或网站产生很多副作用的数据,然而大多数的公司或者网站不清楚如何利用这些数据,仅仅知道他们有时候会用到这些数据。更可悲的是,我们对这些大量数据的结构和意义却完全不了解;这些数据可能是完整的文档,未知的字段,以及不明确的分类。数据大小一般是从TB到PB。这常常被称为“半结构化”数据。
Web流量数据分析可能是数据挖掘中的一个最经典的例子。作为结构化和消息文本的混合形式的数据,一般来自web服务器的日志和cookies。 公司收集这些信息,因为他们想在不使用数据库的情况下,通过这些数据逐渐地建立一个查询的集合和报告,来获取趋势数据。
在数据挖掘解决方案中,最想得到的数据是在高效和快速的情况下,获得CPU的性能和I/O高性能的检索、分类和计算效率。或者,基于多处理器或者多服务器上的并行计算,是最好的结果。对于第二个关注点,数据挖掘数据库常常不得不以每分钟1GB的高速率接受数据。
“我有大量高度结构化的数据,我希望用这些数据生成可视化的结果来帮助商业决策。”
商业活动通常也会产生他们自己很了解的数据:销售数据,客户账户和调查数据。他们希望利用这些数据生成可以策略性地使用的表格,图表和其他好看的图像。这种数据系统有不少形式,包括分析,business intelligence (BI),决策支持(DSS)以及在线分析处理(OLAP)。
我曾经使用来自Point Of Sale (POS) 系统的连锁销售数据部署过这类系统中的两个。POS数据几乎完全由数值,库存ID以及分类树组成,所以它能够创建按类别,时间和地理分类的图表。没有什么必要对这样的数据进行挖掘,因为它已经非常容易理解,而且分类计划的变化很频繁。
大量分析系统功能都集中在分析中间件工具上。用于分析的数据解决方案都是关于大量数据聚合的。像“cubes”(稍后解释)这种支持,对高级分析很有用,这是因为数据被压缩并索引。数据通常通过夜间的批处理导入系统,所以读取方面的快速响应时间没那么重要。
五种类型的数据库
目前市场上,解决数据仓库的这三个基本问题的主要有五种不同类型色数据库系统。这些系统经历了几十年的软件开发。当然,现实生活中的许多大型数据库系统实际上是由以下五种类型混合而成,但我将根据其主要类别列出例子。
如果你只有几十或者上百G的数据,标准主流的关系型数据库仍旧是一个的选择。不管你的选择是 PostgreSQL, MySQL, Oracle, 还是 SQL Server,它们都很成熟,灵活而且有大量第三方和厂商的工具可供使用。或许更重要的是,技术人员已经对它们非常熟悉了。
我为一个小型的连锁零售商的库存管理系统部署了一个分析型数据仓库。最初我们考虑把它设计成一个专有的大型数据库,但是后来我们发现这个数据仓库的最大容量为350G.鉴于此,我们决定采用主流开源的 PostgreSQL,这样一来节省了资金和时间。
标准的关系数据库在数据归档,数据挖掘以及数据分析这些方面都不突出。但是,它们可以胜任所有这些任务。所以如果你的数据仓库问题规模比较小或者不是对响应时间要求严格,它们可以作为一个选择。
MPP数据库是最早为数据仓库设计的数据库,它诞生于20年前。MPP代表“massively parallel processing”,也就是一种单一的查询在多台机器或多个主板上的多处理器执行的关系数据库。数据库管理员喜欢这种类型的数据库,因为他可以把这种数据库当作一个有一定限制的又大又快的关系型数据库服务器。MPP数据库包括 Teradata, Netezza, Greenplum, 以及DB2的数据仓库版。
当我在Greenplum工作的时候,我建立了多个“分析点击量”的数据库,在这些数据库中我们为营销公司处理大量的网络日志数据。我们在日志中没有办法知道我们将会看到什么,甚至网站的页面结构。我们不得不做许多CPU密集型处理:解析文本的聚集,运行自定义数据库函数,并建立实体化的视图,16节点的Greenplum数据库是相当快的。
MPP数据库适用于数据挖掘和分析。其中一些—尤其是Greenplum—也混合了列表中的其他数据库类型。然而,迄今为止,所有产品级的MPP数据库是专有的,任何真正的大数据库通常都非常昂贵。
在1999年发明,列存储数据库致力于改变用于关系型数据库或者“基于行”的数据库的基础存储模型。在基于行的数据库中,数据存储在属性的连续行中,列通过表的元数据相关。列存储数据库把这个模型转了90度,把列的属性存储在一起,而只通过元数据关联行。这允许了不少的优化,包括各种形式的压缩和非常快的聚合。
当前的列存储包括 Vertica, Paraccel, Infobright, LucidDB和 MonetDB. 其中Vertica或许是领先的列存储数据库,后面三个是开源的。此外,一些其他类型的数据库,包括 Aster Data和Greenplum,已经将列存储作为一个选项加入其中。
我们的客户端之一是为一些TB级别的医院绩效数据创建顶层的射线图表。由于所有的这些数据是数字,评级或者保健类别,Vertica被证明是一个很好的解决方案,它用比标准的关系数据库少得多的时间里返回顶层摘要。
列存储仅适合于分析,因为所有的数据必须可以很好的被理解,高度的结构化而被存储于压缩的列中。列存储对于数据有很好的效率,可以减少数字和类别列表的数据。它们主要的缺点是更新或者导入数据缓慢,单行更新基本不可能。
数据仓库的下一个创新是google在不到十年前推广的MapReduce框架。MapReduce是一个算法,当伴随着集群工具,它允许你把单一的请求分为若干小的部分,然后执行于数量巨大的服务器阵列中。当与某种形式的集群或者散列分区存储结合的时候,MapReduce允许用户在数十到数百个节点上执行大量的,长时间运行的请求。Hadoop是占有绝对主导地位的MapReduce框架。当前的基于MapReduce的数据库包括 Hadoop with Hbase, Hadapt, Aster Data, 以及 CouchDB。
在一个项目中,客户需要运行30TB JSON和二进制混合的数据的请求。因为二进制数据的搜索程序是处理器密集型的,它们把这些数据放到HBase并且用Hadoop运行许多的处理程序,把查询结果存储于PostgreSQL中,方便以后的浏览。
在许多方面,MapReduce是开源的,能够替代MPP数据库,而且主要适用于数据挖掘。它可以扩展到较大数量的节点。然而由于它的通用性质,MarReduce在查询方面比MPP低效多了,也更难写了。多亏了诸如 Hive 和 Pig 这样的工具修正了这样的缺点,它们让用户用类似SQL的语法写MapReduce查询。此外,MapReduce数据库比前面的三种要年轻许多,使得它们可靠性和文档化相对差点。
数据仓库中的“新人”是企业搜索。它仅仅包括了两个开源的产品,它们两个都是Apache Lucene项目的后代:Solr和Elastic Search(ES)。企业搜索包括以文件形式在大量的半结构化数据上做多服务器分区索引。二者也都支持“facets”,它是实体化的搜索索引,允许用户通过类别,值,范围和复杂的搜索表达式快速的计算和搜索文档。企业搜索也往往给人“近似”的答案,它可以是一个功能或缺陷,这取决于你的设计目标。
企业搜索在一些令人惊讶的地方是有用的。我们有一个客户端,使用它可以让它们的客户端在非常庞大的法律文件中产生细致入微的汇总统计。把它们放入Solr允许客户端跳过他们需要运行的数据程序而把它放入其他种类的数据库中,同时仍然给它们快速的搜索结果。特别是,Solr索引的预处理计数允许返回文档计数的速度远远超过关系数据库。
企业搜索服务是数据挖掘和分析的一个子集,这使得它具有广泛的用途。它的最大价值发挥在待搜索的数据已经是HTML,XML或者JSON格式的时候,这样不用在索引之前转换或者变换格式。然而,它是最年轻的数据库类型,这两种产品仍旧有许多可靠性问题以及令人惊讶的局限性。此外,数据库请求仍然和“搜索”模型紧密的结合,这让它很难被用在不同的使用情况下。
其它工具
作为所有数据仓库工程的一部分,你同样将需要一些其它的工具,这些工具可以从源中获取数据从而完成你的报告或者接口。鉴于我无法更详细的叙述他们,下边仅罗列出一些你需要知道的工具
加载(Extract Transform Load/ETL)和数据集成工具:这些工具从初始源中获取最终成为数据库格式的数据。代表性的开源加载工具有 Talend 和 KETTLE,而且有许多类似 Informatica 的专属工具。在现代化的基础设施中,像 ActiveMQ 和 RabbitMQ 的开源工具队列平台,许多应用程序所应用的ETL工具正在被自定义代码所取代。
数据挖掘和数据分析工具:像Weka,SAS,以及R language中各式各样的项目所提供的从大量的无序数据中获取意义的高级工具。它们帮助你通过统计学分析和机器学习算法找到你的数据中所存在的模式。在这个领域内,Weka以及R这些开源工具居于行业之首,专有工具主要是用于一些遗留的应用。
报表工具:鉴于你需要展示你的数据,你会需要像 BIRT, JasperReports 这样的报表工具,或者像Business Objects 和 MicroStrategy 这样的专有平台。这些工具可以提供你的数据以简单的可视化效果,通常是很有交互性的图表和图形格式的。近来,这两大代表性的开源工具在易用性方面与专用工具展开了竞争,但是这恐怕要花费他们一些时间去突出他们的特性。
在线分析处理(OLAP):一个欺诈性的名字总是有很多的事情去做,使用“cubes”提供一个基于导航的用户界面去探索你的数据。OLAP工具,像Mondrian,Cognos,以及 Microsoft Analysis Services创建了一个数据的多维空间图,它可以让用户通过在其内不断移动来查看数据的不同部分。这是开源工具十分落后的一块领域;相比于Oracle和SQL Server,开源数据库的OLAP支持就比较弱,Mondrian是仅有的开源OLAP中间件。
我同样需要提及Pentaho,一种集成了所有开源ETL,数据挖掘,报表工具的开源平台。
总的来说,对于所有级别的数据仓库栈都有开源工具,但是这些工具与其竞争对手相比,经常不太完备并且缺乏特性。但是,如今,在分析与数据挖掘领域拥有最先进技术的是开源界,很有可能在将来的3到5年,它们将会达到一个平衡。
结论
现在你应该对数据仓库领域有了比较深的了解,特别是从数据库角度。我们无法深究这些话题的细节或者工程和项目,至少你知道从哪里开始搜索,并且对于每个数据仓库领域都有许多的工具。同样,你可以在最近的波特兰的 Open Source Bridge conference上以视频格式来看这些材料。
翻译:史玉良/李凯
GNU Awk(简称Gawk)是一款通常不会有什么新消息的常用工具。不过其4.0.0发行版却值得期待。Gawk 6月30日宣布,最新版会引入Gawk的首款调试器、用于运行不信任脚本的沙箱模型、内部修订、大量改动的正则表达式以及对IPv6的兼容性。
Gawk是Awk的GNU版本。Awk的名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。它是一个作为跨UNIX平台标准的脚本语言,我这里所说的“标准”是指Awk从一开始就已经成为了标准UNIX系统(或类似UNIX的系统)的一部分,同时它还是由开放组织所提出的POSIX规范的一部分。虽然Gawk只是Awk众多版本之一,但由于广泛应用而脱颖而出。那么它是用来做什么的呢?Gawk虽然也有人用它编写IRC机器人、YouTube下载器、甚至AI编程,但它最著名的是数据处理和分析。
4.0.0中的新特性
Gawk4.0.0较之3.1.8版本有很大的更新。根据发布公告,Gawk不只是封装了大量的新特性、bug修复以及为符合POSIX2008版而做的更新,还包含了一些“内部大修”。
为了找出哪些被更新了以及为什么要更新这些部分,我给Gawk的维护者Arnold Robbins发了封Email。事实表明,这次内部大修有着漫长的历史。Robbins说在几年前John Haque开始用一种字节码引擎来重写Gawk的内核,并且在此过程中引入了一个调试器。不幸的是这项工作并没有被集成进来,并且Haque也转到了其他的工作。在2010年初,Robbins开始尝试把Haque的代码更新到现有程序中。据Robbins说,这次的重写并不会带来性能上的很大改进,不过却引入了一个非常有用的特性:
“性能跟以前的内核相比基本一致(或者略好一些),到目前为止我还没有找到一个case来验证这次改写使得它性能变差了。但是确实因此得到了巨大的好处,这也是为什么我想要做这次改进,gawk现在可以提供一个awk级的调试器(类似于GDB)了。”目前,dgawk 是可用的,但功能受限的。它还不能报告一个错误是什么,当存在问题时只会报告一个“语法错误”。该调试器只能在命令行运行程序时使用,也就是说它不能 attach 到一个运行的Awk程序中。Gawk的开发者们不大可能去添加这项功能,因为Gawk手册中提到,必须用 dgawk 启动程序,才能进行调试,“对于一个主要用于快速执行以及简短程序的编程语言这貌似更加合理的”。
在4.0.0中Gawk的正则表达式发生了一些变化。区间表达式现在成了Gawk默认语法的一部分,并且不再需要 -W或 -POSIX选项了。区间表达式—— 大括号中包含一个或两个数字(形如{n}或{n,m})来告诉Gawk匹配正则表达式n或者从n到m——不再是初始Awk规范的一部分了。此外,\s和\S被加了进来,分别用于匹配任何空白字符和任何不含空白的字符。
虽然Gawk努力兼容POSIX,但它确实有超出POSIX的功能——在4.0.0版本中又引入了一些。Gawk现在支持两种模式,BEGINFILE和ENDFILE,它们分别用于在读取文件之前执行操作以及在读取文件之后执行操作。和BEGIN/END规则类似,不过用于读取每个文件之前和之后(由于Gawk在运行给定脚本时可能会处理两个或更多的文件)。例如,Gawk程序现在可以在处理一个文件之前可以先测试一下文件的可读性。在早期的Gawk版本中是没有这项功能的——因此如果Gawk接收的文件是不可读取的那么一个脚本就会引发一个致命的错误。
Gawk很早就可以用于处理网络连接。在4.0.0版本中,Gawk通过使用/inet6 或 /inet4来强制使用特定协议
网络上充斥着Awk/Gawk脚本,用户可能想要运行这些脚本但又担心的这些脚本会比所宣传的做的更多。为了解决这个问题,Gawk4.0.0中引入了沙箱选项(--sandbox),用于约束Gawk操作特定的输入数据。这项功能是通过禁用Gawk中的system()函数、使用getline的输入重定向以及使用print和printf函数的输出重定向来实现的。
然而,Robbins告诫不要对其表现出的安全性过分相信:
该功能是由一个有特定需要的同志贡献的代码,就我个人观点,如果用 gawk 开发 Web CGI 脚本,此功能很有意义。用户绝不希望 CGI 处理恶意数据的时候被欺骗而导致被注入攻击。从某些方面看沙盒是有意义的,但这个功能不能做出真正的安全承诺。Robbins说沙箱模式在默认情况下是不开启的,因为这将打破“无数现有的awk脚本”。总之,这个选项是有用的,但沙箱选项禁用的功能可能不是恶意脚本损坏用户系统的唯一方式。
4.0.0版本是一些选项和一些旧的不支持的操作系统的终点。--compat,--copyleft,以及--usage等冗余选项都将消失。由于没有被实现,原始套接字选项已经被移除。如果仍然使用Amiga, BeOS, Cray, NeXT, SunOS 3.x, MIPS RiscOS以及其它少数的操作系统,, Gawk 3.1.8是最后能在其上运行的版本。Gawk的团队已取消这些平台的支持其实并不奇怪---因为他们维护的版本已经过期很久了。如今去找一款支持BeOS或者Amiga的专有软件确实是件很有挑战性的事情。
随着Gawk 4.0.0的发行,Robbins说接下来的大项目是把Gawk的三个可执行文件合并为一个版本以此来降低安装空间(gawk、pgawk 用来做profiling、dgawk)。他同时也指出,“针对性能方面,Haque有一些其他的计划,但是我在公共场合只能说这些。”Robbins同时也透漏,计划融入一些XMLgawk扩展(XMLgawk是Gawk的一个扩展,它有一个基于Expat XML程序的XML解析库)。
在Robbins的网站上,还有一些观点列在列在Gawk的路线图上,这其中包括对多精度浮点数MPFR的支持,因此gawk可以使用无限精度的数这字。他指出这会是一项“大工程”,而且还要决定是否默认支持MPFR。Gawk 的理念是代码准备好了才发布,所以对于什么时候Gawk能够具有人们所期望的一些特征,目前来看还没有确切的日期。
Gawk的团队不大,但是他们却是一群核心贡献者支持社区健康运行。Robbins说Gawk团队有六位成员维护着不同的系统,一个测试无数不同的Unix系统,一个贡献者已经帮助完成了文档,还有许多其他人诸如xmlgawk开发者以及来自不同的GNU/Linux发行商。自然的,这还包括Robbins和Haque。
虽然在这些年来Awk不是一种特别性感的语言,但是对于系统管理员以及开发者来说它仍然是一个日常工具。很高兴看到GNU 项目不仅在维护Gawk,还增加一些有趣的新特性来帮助其维护相关的功能。
翻译:马少兵/刘晓佳
在 EuroPython 会议上,Armin Rigo,也就是我本人,已经提过,PyPy 计划删除已经臭名昭著的全局解释器锁,那个妨碍 CPython 多线程并发能力的东东。
Jython 很久以前已经去除了 GIL。它非常小心地给所有 mutable 内置类型加锁,从而达到目的;由于依赖的底层 Java 平台可以较有效的完成实现,这种情况下效率比 CPython 里通过类似的机制达到 GIL-less 要快。另外,“非常小心地”,我的意思是非常非常小心地;例如‘dict1.update(dict2)’,需要同时锁住dict1和dict2,但一个粗糙的实现,也许会导致另一个线程执行‘dict1.update(dict2)’时进入死锁。
PyPy,CPython 以及 IronPython 都依赖 GIL。现在我们正在考虑一种不同于 Jython 这种加锁的机制,而是用 Software Transactional Memory 来去掉 GIL。STM 是计算机科学的一个最新发展,给出了一种不同于锁机制的很好的解决方案。下面通过一个简短的例子说明
假设你想通过pop方法从list1中得到值,并且利用append将该值附加给list2,函数如下:
def f(list1, list2):
x = list1.pop()
list2.append(x)f 并不是线程安全的(甚至在有 GIL 的情况下也是如此)。假设你在thread1中调用f(l1,l2),在thread2中调用f(l2,l1)。你期望线程之间互相之间是没有影响(x将从一个list移动到另外一个,然后返回),但最后结果也许是两个列表的数据发生了交换,这个取决于并发时候的时间顺序。
通过一个全局锁可以防止该错误:
def f(list1, list2):
global_lock.acquire()
x = list1.pop()
list2.append(x)
global_lock.release()
def f(list1, list2):
acquire_all_locks(list1.lock, list2.lock)
x = list1.pop()
list2.append(x)
release_all_locks(list1.lock, list2.lock)第二种解决方案就是 Jython 的模型,而第一种是以Cpython为模型的。的确我们可以看出,在 CPython解释器中,我们获得GIL,执行一个字节码(或者执行100个字节码)以后,然后释放该锁;然后重复上述过程
第三种方案是STM:
def f(list1, list2):
while True:
t = transaction()
x = list1.pop(t)
list2.append(t, x)
if t.commit():
break在这种解决方案下,我们首先需要创建一个事务对象,然后在所有的读写list操作中使用它。上面我们介绍了几种不同的模型,下面我们主要对STM做详细的介绍。在一个事务处理期间,我们不需要改变全局内存,相反使用一个局部线程的事务对象,存储它到一个可以进行读写操作的地方。在这个事务结束前,我们利用“commit”方法提交它。提交的过程可能由于其他的提交此时也在进行而失败,在这种情况下,事务将中止,且必须重新开始。
正如前两个方案分别是CPython和Jython模型, STM方案看起来像是PyPy未来将采用的模型。在这种模型中,解释器会启动一项事务,操作字节码,然后关闭事务,反复这样下去。这与在CPython使用GIL非常类似。特别是,这意味着它给程序员做出和GIL模式一样的保证。唯一的区别是,只要代码不会互相干扰,就能够真正并行运行多个线程。(当然如果你需要的不仅仅是GIL而是多线程程序中的锁,即使有了STM你还是需要获得锁。如果你希望用类似 STM 的机制来避免使用锁的话,也许可以用额外的内建模块将 STM 暴露给Python程序,不过那就是另一个问题了)
为什么不把这种思想应用到CPython中呢?因为这样做的话,我们可能会改变一切。你也许已经注意到了,在上面的例子中,我们不再调用list1.pop()函数,改为调用list1.pop(t);这种方式说明为了实现事务性的完成任务,所有方法的实现都需要改变。这意味着为了避免改变全局内存,必须用 transcation object 记录改变。如果我们的解释器像CPython一样用C写,那么我们需要显式的在每个地方写。相反,如果我们如PyPy那样用高层语言写,我们可以加入这种行为,把它作为解释规则的一部分,然后在需要的地方自动应用。而且,还可以提供一个解释期选项:你可以得到GIL版本“pypy”,或者STM版本。STM 由于增加了额外记录可能会变得更慢。(有多慢?我无法提供线索,但可以猜一猜,也许会慢2-5倍。如果你有足够的CPU内核,只要扩展性够出色,那不是问题。)
最后需要注意:由于STM的研究是最近的事(始于2003年),现在并不确定它的几个变种之中哪个更好。就我目前所了解的,“A Comprehensive Strategy for Contention Management in Software Transactional Memory”[PDF] 看起来是最美好的一种可能,在各种情况下都还不错。
那么什么时候能实现呢?我无法确定。现在仍旧处在创意阶段,不过我想会实现的。需要花多久来写呢?也没有线索,不过我们认为得几个月而不是几天。我打算在9月1日欧洲之星当前的赞助到期后,我就开始全职做这件事情。目前我们打算通过 crowdfunding 的模式融资支持我的全职工作。可能很快就有一篇相关的博客发表,看起来这会是 crowdfunding 的一个很好的案例——我相信至少有数千人愿意花10欧元来去掉GIL。下面就等着我们的消息吧

 本站的feed
本站的feed
最新评论