
翻译:王鑫、朱翊然、李凯、曾怀东、马少兵、林业
时间:2010/09/28
原文地址
The “swap insanity” problem, in brief
在一台包括了2个4核CPU,64GB内存的服务器上,给 MySQL 配置了 48GB 之巨的 InnoDB 缓冲,随着时间的推移,尽管观察到的数据(见最后注1)表示并没有真正的内存压力,Linux 也会把大量的内存交换到磁盘上。通过监控发现,配置的内存超过了实际所需,而且也不存在内存泄漏,mysqld的RSS占用正常且稳定。
通常来说,少量的交换没有什么问题。但在许多情况下,真正有用的内存,尤其是InnoDB缓冲池的主要部分,会被换出。当它再一次被需要时,又会花费很大的性能将它换进,在随机的查询会引起随机的延迟。这可能会在运行系统上造成整体的性能不可预测性,而且一旦开始进行交换,系统可能就会进入性能的“死亡螺旋”。
虽然不是每个系统,或者每个工作负载都会经历这个问题,但是它已经足够普通以至于众所周知,而对于那些十分了解它的人来说,它可能会是一个最主要的麻烦。
The history of “swap insanity”
在过去的二到四年间,已经有过许多关于关闭还是开启Linux swapping和MySQL的讨论,这些总被称为“swap insanity”(我认为这是由Kevin Burton创造的)。我紧密关注这些话题,但是我并没有为此贡献很多,因为我没有添加任何新的东西。在过去的几年间,对此讨论作出主要贡献的是:
- Kevin Burton — 讨论了Linux下的交换和MySQL。
- Kevin Burton — 提出使用IO_DIRECT作为解决方案(并未解决)并且讨论了memlock(可能有所帮助,但仍然不是一个完整的解决方案)。
- Peter Zaitsev — 讨论了交换,内存锁,并且在评论中进行了一系列的展开讨论。
- Don MacAskill — 提出一个创新的方案来 swap 到 ramdisk,相关有很多有趣的讨论
- Dathan Pattishall — 描述了禁止交换后的Linux的行为可能会更糟糕,并且提出了使用swapoff来清除它,但并未真正解决。
- Rik van Riel on the LKML — 给出了一些回答并且提交了Split-LRU补丁
- Kevin Burton — 讨论了Linux Split-LRU补丁的一些成功之处。
- Mark Callaghan — 讨论了vmstat和监控方面的事情,并且回顾了一些可能的解决方案。
- Kevin Burton — 更多地讨论了Linux Split-LRU是优秀的。
- Kevin Burton — 通过开启了交换而选择了一种折中的方法,但是这样只有少量空间,而且放弃了这场斗争
- Peter Zaitsev — 更多地讨论了为什么交换是糟糕的,但是依然没有解决方法。
尽管有这么多的这论,但是并没有带来太多的改变。有一些类似于“黑客式”的解决方法来使得MySQL停止交换,但是什么都不能确定。我已经了解这些解决方案和黑客式的手法一阵子了,但是核心的问题从来没有解决:“为什么会发生这?”还有它从来不适合我。我最近尝试去理顺这个问题,希望能够一劳永逸地解决它。因此到目前为止我做了大量关于这个问题的研究和测试。我学到了很多,我认为写一篇博客可能是会分享它的最佳途径。希望大家喜欢。
从几年前,已经有许多讨论和一些工作进入了加入相对较新的交换方法的调整的方面,我认为那可能已经解决了一些原始问题,但是此刻,机器的基础架构已经变为了NUMA,我认为这引入了一些新的问题,这些问题有着极为相似的症状,并且掩去了原始问题修订的成功。
对比SMP/UMA和NUMA两种架构
The SMP/UMA architecture
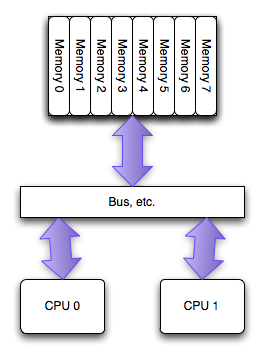
当PC领域最初拥有多处理器时,它们能够机会均等的进入系统中的所有内存。这叫做对称多处理器(SMP), 或者有时候叫统一访存架构(UMA,特意和NUMA进行对比)。在过去的几年中,每个 socket 上的单个处理器之间访问内存已经不再使用这种架构,但是在每一个处理器的多个核之间仍然盛行:所有的内核拥有均等的进入内存的机会。
The NUMA architecture
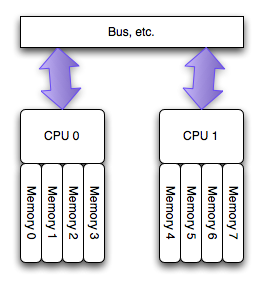
运行在 AMD Opteron 和 Inter Nehalem 处理器(见注2)上的多处理器的新的架构,叫做非匀称访存架构(NUMA),更确切的说是一致性缓存非匀称存储访问架构(ccMUMA)。在该架构中,每个处理器拥有一个“本地的”存储体,使用它可以较快的访问(延迟小)。整个的系统仍旧可以以整体的形式运行,从任何地方访问所有的内存,但是这样有潜在的高延迟和低性能的可能。
从根本上来说,“本地”的那些内存访问会快些,也就是说,可以比其他的地址(“远程”的和其他处理器关联的那些)以更小的代价访问。如果想得到更详细的关于NUMA实现的讨论以及它在Linux的支持,请去lwn.net上看 Ulrich Drepper 的文章。
How Linux handles a NUMA system
当运行在NUMA架构系统上时,Linux会自动的知道这个事实,并且做以下的事情:
- 枚举硬件设施,用来得知物理的布局。
- 把处理器(并非内核)分成不同“节点”。对于现代的PC处理器,不考虑内核的数量的话,这意味着一个节点对应一个物理处理器。
- 将系统中的每个内存模块和它本地处理器的节点绑定在一起。
- 收集内部节点通信的代价信息(节点间的“距离”)。
你可以用numactl --hardware命令查看linux是怎么枚举你系统上NUMA的布局
# numactl --hardware available: 2 nodes (0-1) node 0 size: 32276 MB node 0 free: 26856 MB node 1 size: 32320 MB node 1 free: 26897 MB node distances: node 0 1 0: 10 21 1: 21 10
输出结果里讲了这么几件事情:
- 节点的数量以及这些节点的编号 — 这个例子中,两种节点被标识为0和1
- 每个节点中可用内存的数量 — 一台双核计算机共有64G的内存,所以在每个节点上理论上可以分得32G内存。但必须指出的是,在这里并不是把64G的内存平均分配,这是因为每个节点的内核需要消耗一些内存。
- 节点之间的“距离” — 它是从节点1访问节点0上的内存时,所付出的代价的一种表现形式。这个例子里,linux为本地内存声明距离为“10”,为非本地内存声明的距离为“21”
NUMA是如何改变 Linux 工作模式的
从技术层面来说,只要一切运行良好,UMA或者NUMA是没有理由在OS水平级上去改变运行方式。然而,如果要获得最好的性能,那么需要要做一些额外的工作,直接去处理NUMA底层的一些事情。如果把CPU和内存当作一个黑盒子,那么linux会做以下一些意想不到的事情:
- 每一个进程和线程都继承成它们的父结点的 NUMA 策略。每个线程都可以修改成独立的策略。策略包括该进程/线程可在哪些 CPU 甚至内核上运行,从哪里的内存插槽上申请内存,以及上述两项限制有多严格
- 初始化时,每一个线程都被分配到一个“首选”的节点上去运行。该线程可以运行在其他任何地方(如果策略允许),但是调度器试图保证它始终运行在首选的结点上。
- 为进程分配的内存被分配在一个特定的节点上,默认情况下是“current”,这意味着相应的线程会首选在同一个节点上运行。在UMA/SMP架构上,所有的内存是一视同仁的,并且有相同的开销。但是系统如今已经开始考虑它从何而来,这是因为访问非本地内存对性能是有影响的,并可能导致高速缓存的一致性延迟。
- 无论系统需不需要,分配到一个节点的内存肯定不会移动到另一个节点上去。一旦内存分配到一个节点上,那么它将一直留在那里。
使用numactl这样非常简单的程序,使得任何进程的NUMA策略都是可以改变的,具有广泛深远的影响。除此还能做些额外的工作,即通过链接到libnuma并写一些代码去管理策略,可以使其在细节上做些微调。简单的应用numactl已经可以做一些有趣的事情:
- 用特殊的策略分配内存
- 使用 current 节点 — using --localalloc, and also the default mode
- 使用某个节点,但是如果有必要也能使用其他的节点 — using --preferred=node
- 总是使用某个或某组节点 — using --membind=nodes
- 交错使用(round-robin )所有节点 — using --interleaved=all or --interleaved=nodes
- Run the program on a particular node or set of nodes, in this case that means physical CPUs (--cpunodebind=nodes) or on a particular core or set of cores (--physcpubind=cpus).
What NUMA means for MySQL and InnoDB
InnoDB以及其他所有数据库服务器( 包括 Oracle 在内),对linux来说都表现为非典型的工作负载(以大多数程序的角度):一个单一庞大的多线程进程消耗了系统几乎所有的内存,并且将会不断消耗系统剩余资源。
在基于NUMA的系统中,内存被分配到各个节点,系统如何处理这点不是那么简单。系统的默认行为是为进程运行所在的同一个节点分配内存,这种方式在内存量比较少的情况下效果不错,但是当你希望分配超过半数的系统内存时,这种方式即便只应用于单一NUMA节点,在物理层面上也变得不再可行:在双节点系统,每个节点中只有50%的内存。另外,由于大量不同的查询操作会同时运行在两个处理器上,任何一个单独的处理器都无法优先获取特定查询所需的那部分特定内存。
这显然非常重要。使用 /proc/pid/numa_maps 我们可以看到所有mysqld做的分配操作,还有一些关于它们的有意思的信息。如果你进行大量的查找,anon=size,你可以轻易的发现缓存池(它会消耗超过51GB的内存,超过了设置的48GB)
2aaaaad3e000 default anon=13240527 dirty=13223315 swapcache=3440324 active=13202235 N0=7865429 N1=5375098
显示的各字段如下:
- 2aaaaad3e000—内存区域的虚拟地址。实际上可以把这个当做该片内存的唯一ID。
- default —这块内存所用的NUMA策略
- anon=number—映射的匿名页面的数量
- dirty=number —由于被修改而被认做脏页的数量。通常在单一进程中分配的内存都会被使用,变成脏页。但是如果产生一个新进程,它可能有很多copy-on-write pages映射(写时复制页),这些可能不是脏页。
- swapcache=number —被交换出但是由于被交换出所以没有被修改页面的数量。这些页面可以在需要的时候被释放,但是此刻仍然在内存中。
- active=number —在“激活列表”中的页面的数量;如果显示了该字段,那么部分内存没有激活(anon减去active),这也意味着这些可能很快被swapper交换出去。
- N0=number and N1=number —节点0和节点1上各自分配的页面的数量。
整个numa_maps可以用一个简单的脚本 numa-maps-summary.pl 进行快速的总结,这个脚本是我自己编写用于分析这个问题的:
N0 : 7983584 ( 30.45 GB) N1 : 5440464 ( 20.75 GB) active : 13406601 ( 51.14 GB) anon : 13422697 ( 51.20 GB) dirty : 13407242 ( 51.14 GB) mapmax : 977 ( 0.00 GB) mapped : 1377 ( 0.01 GB) swapcache : 3619780 ( 13.81 GB)
我发现了两件有趣并出乎意料的事情:
- 节点0和节点1间内存分配的绝对不平衡。实际上根据默认策略这显然很正常。使用默认NUMA策略,内存优先分配给节点0,节点1被用作备份。
- 大量的内存被分配到节点0。这是关键 — 节点0用尽了空闲内存!它总共只有32GB内存,同时它分配了一个超过30GB的内存块放在InnoDB的缓存池中。一些其他进程分配的少量内存把剩余内存耗尽,此刻没有任何剩余内存也无法进行任何缓存。
下图显示的是MySQL数据库的内存分配图:
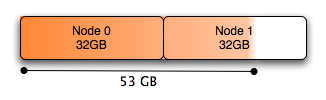
总体来说,Node 0几乎完全耗尽了空闲的内存,尽管系统有大量的空闲内存(将近有10G用于缓存)给Node 1.如果位于Node 0上的进程调度需要大量的本地内存的话,就会导致已经分配了任务的内存被交换,以满足一些Node 0页面的需要。尽管Node 1上存在大量的内存,但是在许多情况下(对这点,到现在我还不理解,见注3),Linux系统内核宁愿将Node 0上已分配任务的内存交换,也不愿使用Node 1上空闲的内存容量。因为页面调度远远比本地内存处理花销更大。
小变化,大效果
上述问题最容易的解决方案是交叉分配内存,运行:
# numactl –interleave all command
我们可以凭借将脚本mysqld_safe.sh只改动一行,在脚本中添加(cmd="$NOHUP_NICENESS"),使得在启动mysql命令前,启动numactl命令。该脚本为已添加(cmd="$NOHUP_NICENESS")命为的内容:
-
cmd="$NOHUP_NICENESS"
-
cmd="/usr/bin/numactl --interleave all $cmd"
-
for i in "$ledir/$MYSQLD" "$defaults" "--basedir=$MY_BASEDIR_VERSION"
-
"--datadir=$DATADIR" "$USER_OPTION"
-
do
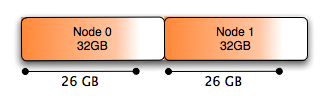
修改配置后,会发现当MySQL需要内存得时候,它将采用交叉分配的方式,给所有节点进行分配,使得每个节点都承载有效平衡的内存分配。同时也会在每个节点上留下一些空闲的内存空间,允许Linux内核在两个节点之间缓存数据,这种方式仅仅释放缓存的时候(当支持这种情况的时候工作),才允许任何一点节点内存容易释放,而不是页面调度的时候。
通过性能回归测试,我们已比较了两种情况下的性能,使用DBT2标准检测程序(本地内存+溢出内存----交叉内存),最终发现:在一般情况下的性能是等同的,这是可以预料的。突破发生在下面情况:使用交换的所有案例,在重复使用的情况下,系统不再发生交换。
你会看到所有采用numa_maps(NUMA: 非一致内存访问)分配的内存平均分布在Node 0和1上:
2aaaaad3e000 interleave=0-1 anon=13359067 dirty=13359067 N0=6679535 N1=6679532
And the summary looks like this:
N0 : 6814756 ( 26.00 GB) N1 : 6816444 ( 26.00 GB) anon : 13629853 ( 51.99 GB) dirty : 13629853 ( 51.99 GB) mapmax : 296 ( 0.00 GB) mapped : 1384 ( 0.01 GB)
图形表示就是这样
关于 zone_reclaim_mode 的一些题外话
配置 /proc/sys/vm 中的 zone_reclaim_mode 可以用来调整 NUMA 系统的内存回收策略。从 linux-mm 列表中的一些讨论表明,该配置对本例子不会改善。
一个更好的解决方案?
我觉得(也得到了linux-mm邮件列表的支持)一定还有更大的优化空间。尽管至今为止我任何的测试都没做。交错化分配是一个方法,如果它真的解决了这个问题的话,我想一个更好的方案就是,使用 libnuma 智能化对待 NUMA 架构。下边是一些涌现出来的想法:
- Spread the buffer pool across all nodes intelligently in large chunks, or by index, rather than round-robin per page.
- Keep the allocation policy for normal query threads to “local” so their memory isn’t interleaved across both nodes. I think interleaved allocation could cause slightly worse performance for some queries which would use a substantial amount of local memory (such as for large queries, temporary tables, or sorts), but I haven’t tested this.
- Managing I/O in and out to/from the buffer pool using threads that will only be scheduled on the same node that the memory they will use is allocated on (this is a rather complex optimization).
- Re-schedule simpler query threads (many PK lookups, etc.) on nodes with local access to the data they need. Move them actively when necessary, rather than keeping them on the same node. (I don’t know if the cost of the switch makes up for this, but it could be trivial if the buffer pool were organized by index onto separate nodes.)
我不知道以上的想法是否有哪些真的可以在一个真实系统中展现出特别优点,但是我很希望能得到评论或者其它的观点。
====== 这是华丽丽的分割线 =========
- 注1 使用 free 命令来观察内存以及 cache 使用情况,使用 ps 或者 top 命令可以观察 resident set sizes.
- 注2 Dr. Dobb's Journal 上的文章A Deeper Look Inside Intel QuickPath Interconnect给了一个很棒的概况介绍. Intel published a paper entitled Performance Analysis Guide for Intel® CoreTM i7 Processor and Intel® XeonTM 5500 processors which is quite good for understanding the internals of NUMA and QPI on Intel’s Nehalem series of processors.
- 注3 我最开始在 linux-mm 邮件列表上讨论 MySQL on NUMA, 这里还有两个相关的讨论线索:zone_reclaim_mode 和 swapping

 本站的feed
本站的feed
最新评论